وقتی حجم داده زیاد می شود و سیستم ها باید همزمان، سریع و بدون توقف با هم ارتباط داشته باشند، روش های سنتی کم می آورند. اینجاست که سوال Apache Kafka چیست مطرح می شود. Apache Kafka چیست فقط یک ابزار نیست، بلکه یک ستون اصلی برای انتقال داده در مقیاس بزرگ است. اگر با سیستم های توزیع شده، پردازش رویداد یا داده های لحظه ای سر و کار داری، شناخت Kafka برایت ضروری می شود.
Apache Kafka چیست و از کجا آمده است
Apache Kafka یک پلتفرم توزیع شده برای پردازش و انتقال جریان داده است که ابتدا در لینکدین توسعه داده شد و بعد به بنیاد Apache منتقل شد. هدف اصلی Kafka مدیریت حجم بالای داده با سرعت بالا و قابلیت اطمینان بود. Kafka طوری طراحی شده که بتواند میلیون ها پیام را در ثانیه دریافت، ذخیره و توزیع کند، بدون اینکه سیستم دچار گلوگاه شود.
مشکل اصلی در سیستم های توزیع شده
در سیستم های توزیع شده، بخش های مختلف معمولا به داده های مشترک نیاز دارند. اگر این ارتباط مستقیم باشد، هر اختلالی می تواند کل سیستم را تحت تاثیر قرار دهد. Kafka این مشکل را با جدا کردن تولیدکننده و مصرف کننده داده حل می کند. سرویس ها دیگر مستقیما با هم حرف نمی زنند، بلکه داده را منتشر می کنند و هر مصرف کننده ای که نیاز داشته باشد، آن را دریافت می کند.
معماری کلی Apache Kafka
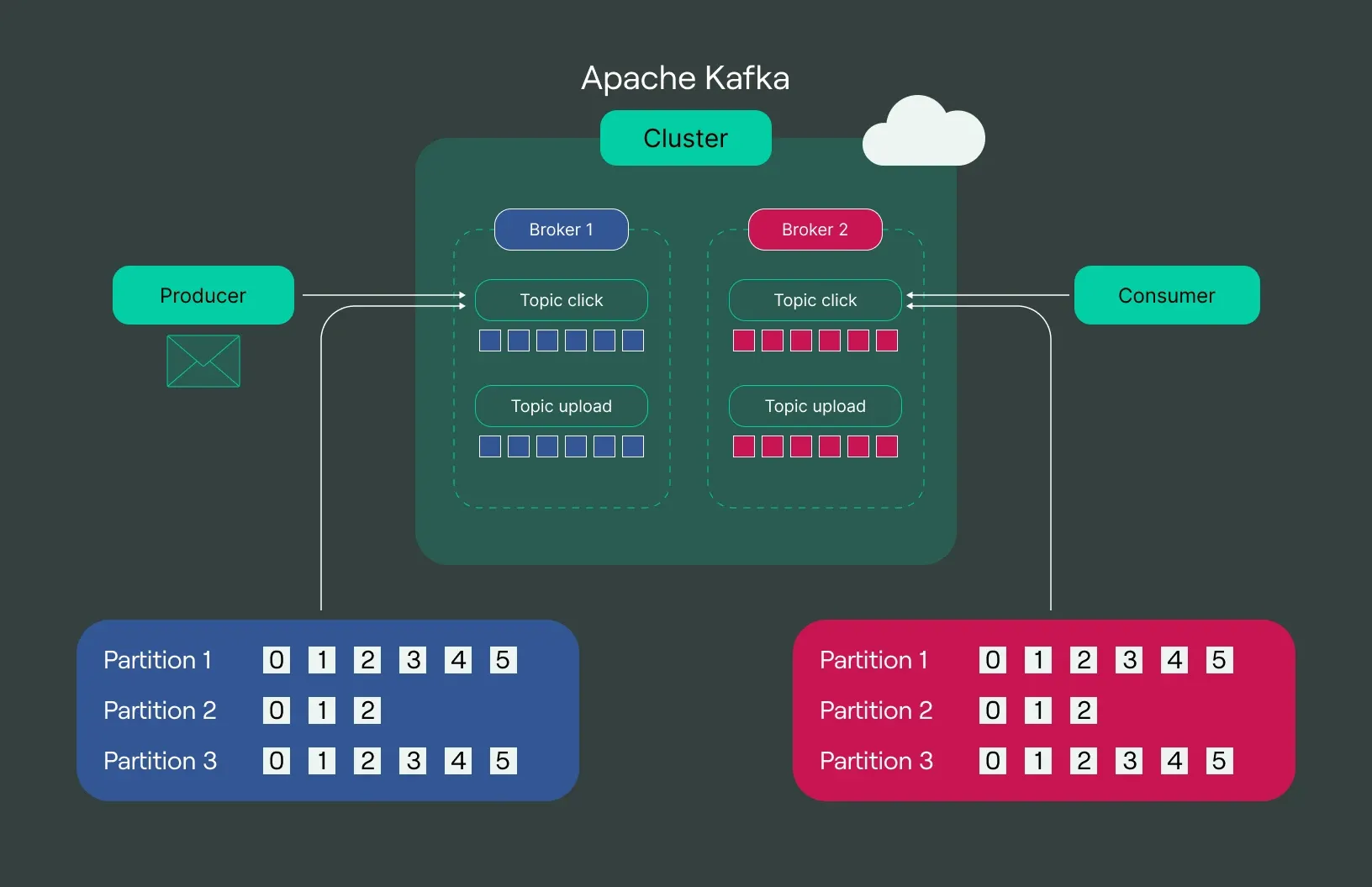
معماری Kafka ساده به نظر می رسد، اما بسیار قدرتمند است. در مرکز آن یک کلاستر Kafka قرار دارد که از چندین Broker تشکیل شده است. داده ها به صورت پیام در Topic ها ذخیره می شوند. هر Topic به بخش هایی به نام Partition تقسیم می شود تا پردازش موازی امکان پذیر شود. این معماری باعث می شود Kafka هم سریع باشد و هم مقیاس پذیر.
Producer و Consumer در Kafka
Producer سیستمی است که داده را به Kafka ارسال می کند. Consumer سیستمی است که داده را از Kafka می خواند. این دو کاملا مستقل از هم هستند. Producer اهمیتی نمی دهد چه کسی داده را می خواند و Consumer هم نیازی به دانستن منبع داده ندارد. این استقلال، یکی از دلایل اصلی استفاده از Kafka در سیستم های بزرگ است.
Topic و Partition چه نقشی دارند
Topic را می توان یک کانال منطقی برای داده در نظر گرفت. هر نوع داده معمولا Topic مخصوص خود را دارد. Partition باعث می شود داده ها در یک Topic به چند بخش تقسیم شوند. این کار امکان پردازش همزمان و توزیع بار را فراهم می کند. هر Partition ترتیب پیام های خودش را حفظ می کند و همین موضوع برای بسیاری از کاربردها حیاتی است.
Broker و Cluster در Kafka
Broker یک سرور Kafka است که پیام ها را ذخیره و مدیریت می کند. چند Broker کنار هم یک Cluster را تشکیل می دهند. اگر یکی از Broker ها از دسترس خارج شود، بقیه همچنان کار می کنند. Kafka با این طراحی، تحمل خطای بالایی دارد و برای سیستم هایی که توقف در آنها قابل قبول نیست، انتخاب مناسبی است.
نحوه ذخیره سازی داده در Kafka
برخلاف بسیاری از صف های پیام، Kafka داده ها را برای مدت مشخصی نگه می دارد. حتی اگر Consumer پیام را بخواند، داده بلافاصله حذف نمی شود. این ویژگی باعث می شود بتوان داده ها را دوباره پردازش کرد یا Consumer جدید اضافه کرد. Kafka بیشتر شبیه یک لاگ توزیع شده عمل می کند تا یک صف پیام سنتی.
مدیریت Offset و خواندن داده
هر Consumer موقع خواندن داده، یک Offset دارد که مشخص می کند تا کجای Topic را خوانده است. این Offset به Consumer اجازه می دهد کنترل کاملی روی خواندن داده داشته باشد. اگر Consumer ریست شود، می تواند از همان نقطه ادامه دهد یا دوباره از ابتدا بخواند. این انعطاف یکی از نقاط قوت Kafka است.
Apache Kafka چگونه مقیاس پذیر می شود
مقیاس پذیری در Kafka به صورت افقی انجام می شود. با اضافه کردن Broker های جدید، ظرفیت سیستم افزایش پیدا می کند. Partition ها بین Broker ها توزیع می شوند و بار کاری متعادل می شود. این طراحی باعث شده Kafka بتواند در مقیاس بسیار بزرگ بدون افت عملکرد کار کند.
تضمین تحویل پیام در Kafka
Kafka امکان تنظیم سطوح مختلف اطمینان را فراهم می کند. می توان مشخص کرد پیام حتما روی چند Broker ذخیره شود یا نه. همچنین Consumer می تواند بعد از پردازش موفق، Offset را ثبت کند. این تنظیمات کمک می کنند بین سرعت و اطمینان تعادل ایجاد شود، بسته به نیاز پروژه.
تفاوت Kafka با Message Queue های سنتی
Kafka فقط یک Message Queue نیست. صف های سنتی معمولا پیام را بعد از مصرف حذف می کنند، اما Kafka داده را نگه می دارد. همچنین Kafka برای پردازش جریان داده طراحی شده، نه فقط ارسال پیام. این تفاوت باعث می شود Kafka برای تحلیل داده، مانیتورینگ و پردازش رویداد بسیار مناسب باشد.
کاربردهای رایج Apache Kafka
Kafka در سناریوهای زیادی استفاده می شود. پردازش رویداد، لاگ گیری مرکزی، تحلیل داده های بلادرنگ، انتقال داده بین سیستم ها و معماری Event Driven از کاربردهای رایج آن هستند. شرکت های بزرگ از Kafka برای مدیریت داده در مقیاس بالا استفاده می کنند، چون قابل اعتماد و سریع است.
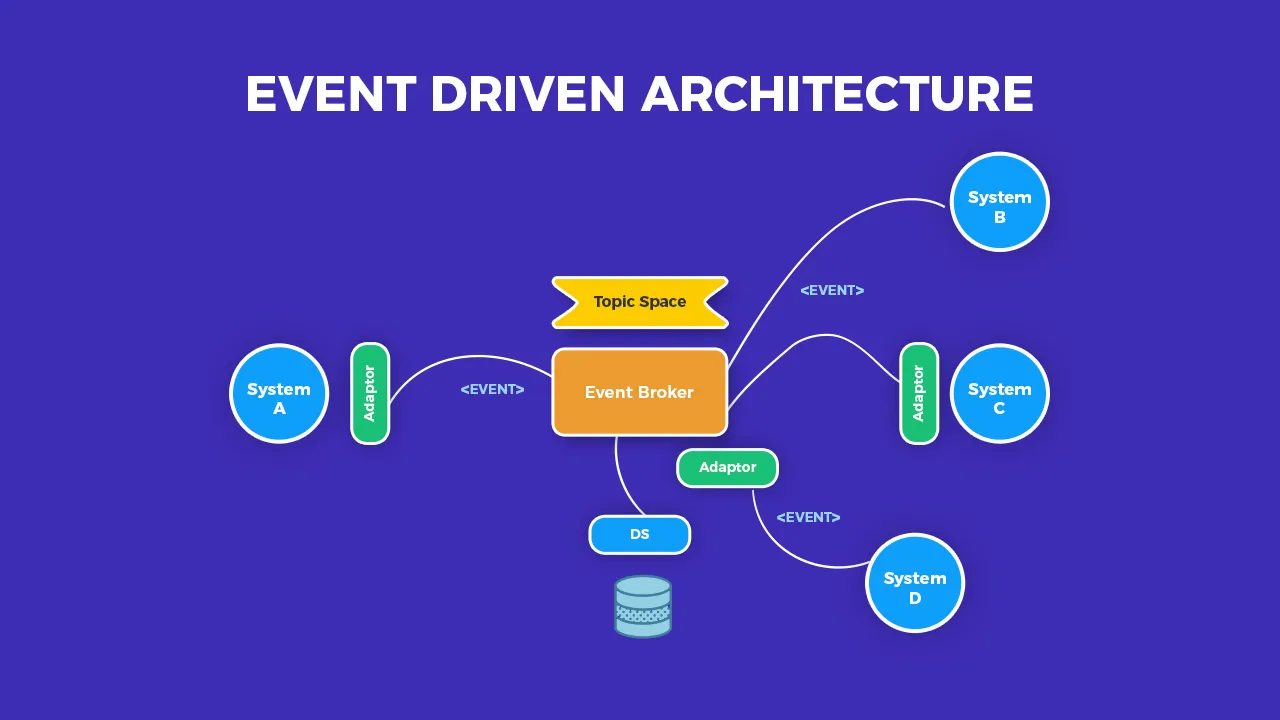
Kafka در معماری Event Driven
در معماری Event Driven، هر اتفاق یک رویداد است که منتشر می شود. Kafka بستری عالی برای این نوع معماری فراهم می کند. سرویس ها رویدادها را منتشر می کنند و بقیه سرویس ها در صورت نیاز به آنها واکنش نشان می دهند. این مدل باعث می شود سیستم انعطاف پذیرتر و توسعه پذیرتر شود.
چالش ها و محدودیت های Kafka
با تمام مزایا، Kafka پیچیدگی خاص خودش را دارد. راه اندازی و نگهداری آن نیاز به دانش فنی دارد. تنظیم نادرست Partition یا Replication می تواند باعث مشکلات عملکردی شود. همچنین Kafka برای کارهای ساده شاید بیش از حد سنگین باشد. به همین دلیل استفاده از آن باید آگاهانه باشد.
Apache Kafka در دنیای امروز
امروزه Kafka یکی از ابزارهای کلیدی در زیرساخت داده محسوب می شود. اکوسیستم آن رشد زیادی کرده و ابزارهای مکمل زیادی دارد. این موضوع نشان می دهد Kafka یک راه حل موقتی نیست، بلکه بخشی جدی از معماری سیستم های مدرن است.
جمع بندی
Apache Kafka راهکاری قدرتمند برای مدیریت جریان داده در سیستم های توزیع شده است. سرعت بالا، تحمل خطا و مقیاس پذیری آن را به انتخابی محبوب تبدیل کرده است. اگر بدانی Apache Kafka چیست و چه کاربردی دارد، می توانی سیستم هایی طراحی کنی که در برابر حجم بالا و تغییرات ناگهانی مقاوم باشند. این شناخت، پایه معماری های مدرن و پایدار است.