
4دقیقه
آنچه در این مقاله میخوانید [پنهانسازی]
با گسترش مدلهای زبانی بزرگ و نیاز به پردازش دقیقتر و سریعتر زبان طبیعی، مهندسان و پژوهشگران در پی یافتن راهکارهایی برای افزایش توان پردازشی، کاهش مصرف منابع و افزایش دقت بودند. یکی از مهمترین دستاوردها در این زمینه، معرفی معماری Switch Transformer از سوی گوگل بود؛ مدلی که با استفاده از ایده Mixture of Experts (MoE) توانست به طرز چشمگیری مقیاسپذیری و بهرهوری را در مدلهای زبانی ارتقا دهد. این معماری با کاهش بار محاسباتی و در عین حال حفظ کیفیت، راه را برای توسعه مدلهایی با بیش از یک تریلیون پارامتر هموار کرد.
سرفصل های مقاله
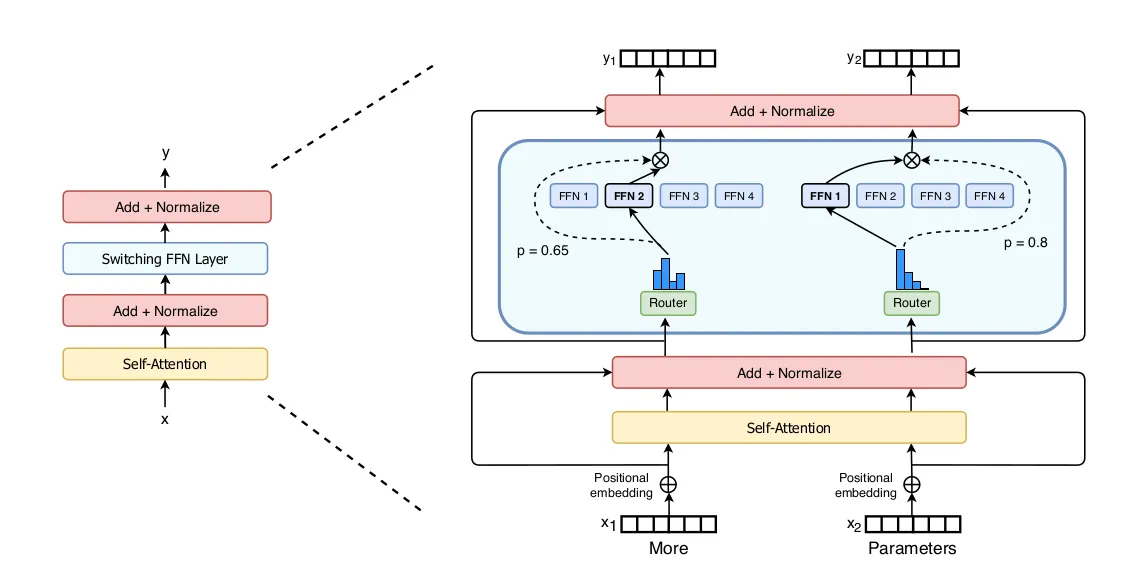
Switch Transformer یک نسخه بهینهشده و سادهشده از معماری MoE است که توسط تیم تحقیقاتی گوگل معرفی شد. ایده اصلی در MoE این است که بهجای فعال کردن تمام واحدهای مدل در هر گام محاسباتی، فقط چند ماژول تخصصی (یا به اصطلاح “متخصص”) فعال شوند. Switch Transformer این ایده را سادهتر کرد و در هر لایه فقط یک متخصص را برای فعالسازی انتخاب میکند، که هم زمان پردازش را کاهش میدهد و هم مصرف حافظه را به حداقل میرساند.
در مدلهای سنتی، تمامی پارامترهای یک لایه فعال میشوند، حتی اگر بخشی از آنها برای آن داده خاص مورد نیاز نباشند. اما Switch Transformer با استفاده از سوییچینگ بین متخصصها، تنها بخشی از پارامترها را فعال میکند. نتیجه آن، صرفهجویی چشمگیر در منابع محاسباتی است بدون آنکه دقت مدل فدای سرعت شود.
برای مثال، در یک مدل با ۱۰۰ متخصص، در هر گام فقط یکی از آنها فعال میشود. با این روش، میتوان مدلی با بیش از یک تریلیون پارامتر ساخت، اما فقط ۱٪ از آن در هر گام استفاده شود. این معماری در عین سادگی، قدرتی بینظیر را به مدلهای زبانی داده است.
آموزش هوش مصنوعی (صفر تا صد کار با ابزارهای هوش مصنوعی)
هر لایه در Switch Transformer شامل چندین مسیر مستقل (متخصص) است. وقتی یک ورودی وارد مدل میشود، یک router با استفاده از یک تابع یادگیریپذیر تصمیم میگیرد کدام متخصص برای این ورودی مناسبتر است.
در اکثر پیادهسازیها، تنها یک متخصص در هر گام برای هر ورودی فعال میشود. این تصمیم منجر به کاهش چشمگیر مصرف حافظه، تسهیل آموزش و تسریع در inference میشود.
Switch Transformer بهصورت end-to-end آموزش داده میشود، یعنی انتخاب متخصص، اجرای عملیات و بهروزرسانی وزنها همه در یک فرایند یکپارچه صورت میگیرد. همین یکپارچگی باعث پایداری بهتر در آموزش مدلهای بزرگ شده است.
| ویژگی | توضیح |
|---|---|
| کاهش بار محاسباتی | تنها بخشی از مدل فعال میشود، در نتیجه مصرف منابع کاهش مییابد. |
| مقیاسپذیری بسیار بالا | میتوان مدلهایی با تریلیونها پارامتر را بدون نیاز به منابع نامعقول اجرا کرد. |
| حفظ دقت | در مقایسه با مدلهای dense با همان سطح مصرف منابع، Switch عملکرد بهتری دارد. |
| سادگی پیادهسازی | برخلاف MoEهای کلاسیک، پیچیدگی کمتری دارد. |
| قابلیت اجرا روی TPU و GPU | با استفاده از GShard یا TensorFlow Mesh، به سادگی قابل استقرار است. |
این معماری بهطور مستقیم در ساخت مدلهای زبانی عظیم مانند PaLM و GLaM استفاده شده است که در ترجمه، درک متن، خلاصهسازی و پرسشپاسخ عملکرد چشمگیری داشتند.
مدلهایی که با Switch Transformer ساخته شدهاند، در سیستمهای ترجمه گوگل استفاده شدهاند و بهبود محسوسی در کیفیت ترجمه زبانهای کممنبع ایجاد کردهاند.
با توجه به صرفهجویی محاسباتی، این مدلها گزینهای مناسب برای استفاده در Agentهای هوشمند و چتباتهای real-time هستند که نیاز به پاسخدهی سریع و دقیق دارند.
| ویژگی | Switch Transformer | GPT-3 | BERT | T5 |
|---|---|---|---|---|
| نوع معماری | Sparse MoE | Dense | Dense | Encoder-Decoder |
| مصرف حافظه | پایین | بالا | متوسط | بالا |
| تعداد پارامتر قابلاستفاده در inference | بسیار پایین | بالا | بالا | بالا |
| دقت در وظایف زبانی | بالا | بالا | بالا | بسیار بالا |
| سرعت inference | بسیار بالا | پایین | متوسط | پایین |
گوگل با استفاده از Switch Transformer، توانست مدلهایی بسازد که:
همچنین از این معماری در پروژههای ترجمه، خلاصهسازی اخبار و پاسخدهی به سؤالات در موتور جستجوی گوگل نیز استفاده شده است.
با رشد ابزارهای توزیعشده مانند Mesh TensorFlow و GSPMD، انتظار میرود Switch Transformer پایه بسیاری از مدلهای مولتیماژول و هوشمند آینده باشد. این معماری نهتنها برای مدلهای زبان، بلکه برای بینایی کامپیوتر، تحلیل صوت و حتی بازیسازی نیز قابل استفاده خواهد بود.
Switch Transformer انقلابی در طراحی مدلهای بزرگ زبانی است. با فعالسازی تنها بخشی از مدل، این معماری توانست هم سرعت، هم دقت و هم بهرهوری را بهبود دهد. بسیاری از مدلهای پیشرفته امروزی مدیون این ایده هوشمندانه هستند. بدون شک، آینده مدلهای هوش مصنوعی به معماریهای sparse مانند Switch Transformer تعلق دارد.

با رشد سریع هوش مصنوعی و گسترش استفاده از مدلهای زبانی، نیاز به روشی ساده و سریع برای اتصال این مدلها به ابزارها...

با گسترش ابزارهای هوش مصنوعی، دو مفهوم پرکاربرد بیشتر از همیشه شنیده میشود: AI Agent و MCP. هرچند هر دو به نحوی به...

پرامپتها (Prompts) قلب تعامل ما با مدلهای هوش مصنوعی هستند. نحوه طراحی پرامپت میتواند خروجی مدل را به شدت تحت تأثیر قرار دهد....

با گسترش هوش مصنوعی، شرکتها به دنبال مدلهایی هستند که هم کارایی بالا داشته باشند و هم در منابع سختافزاری سبکتر عمل کنند....

جامعه توسعهدهندگان همیشه به دنبال ابزارها و پرامپتهایی است که کار با مدلهای هوش مصنوعی را سادهتر و کارآمدتر کنند. یکی از پلتفرمهایی...