وقتی تعداد سرورها زیاد می شود، دیگر نمی شود فقط با نگاه کردن به لاگ ها یا حدس زدن وضعیت سیستم جلو رفت. اینجا مانیتورینگ تبدیل به یک ضرورت می شود، نه یک ابزار لوکس. prometheus در DevOPS دقیقا برای همین ساخته شده است؛ اینکه بدانی سیستم الان چه وضعیتی دارد، چه چیزی در حال خراب شدن است و کجا باید قبل از بحران واکنش نشان بدهی.
مانیتورینگ سرور یعنی چه و چرا مهم است
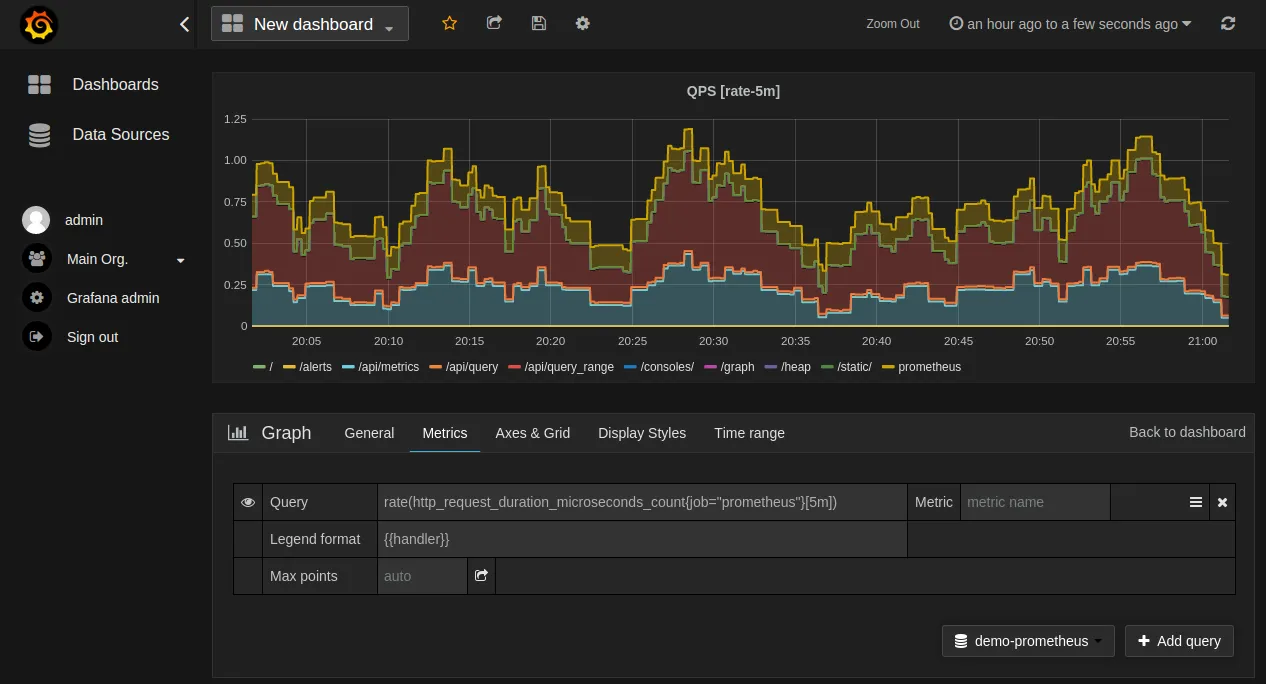
مانیتورینگ یعنی جمع آوری، ذخیره و تحلیل داده هایی که وضعیت سیستم را نشان می دهند. مصرف CPU، حافظه، دیسک، تعداد درخواست ها، خطاها و تاخیرها همه بخشی از این تصویر هستند. بدون مانیتورینگ، مشکل زمانی دیده می شود که کاربر شکایت کرده است. با مانیتورینگ درست، مشکل قبل از رسیدن به کاربر شناسایی می شود.
Prometheus چیست و چه مشکلی را حل می کند
Prometheus یک سیستم مانیتورینگ متن باز است که بر اساس جمع آوری متریک ها کار می کند. به جای اینکه سرورها اطلاعات را بفرستند، Prometheus خودش به صورت دوره ای متریک ها را از سرویس ها می خواند. این مدل باعث می شود کنترل کامل روی مانیتورینگ داشته باشی و وابسته به عامل های پیچیده نباشی.
جایگاه prometheus در DevOPS
در فرهنگ DevOPS، هدف شفافیت و واکنش سریع است. prometheus در DevOPS نقش چشم سیستم را بازی می کند. توسعه دهنده و تیم عملیات هر دو به یک منبع مشترک از داده نگاه می کنند. این یعنی تصمیم گیری بر اساس واقعیت، نه حدس. وقتی متریک ها شفاف باشند، اختلاف نظر کمتر می شود.
معماری Prometheus به زبان ساده
Prometheus چند بخش اصلی دارد. سرور Prometheus که داده ها را جمع آوری و ذخیره می کند. Exporter ها که متریک ها را از سیستم یا سرویس ها بیرون می آورند. پایگاه داده زمانی که متریک ها را نگه می دارد. و در نهایت سیستم هشدار که روی این داده ها واکنش نشان می دهد. این معماری ساده اما بسیار قدرتمند است.
مفهوم Pull Model در Prometheus
برخلاف خیلی از سیستم ها، Prometheus از مدل Pull استفاده می کند. یعنی خودش می رود و داده ها را می گیرد. این مدل باعث می شود اگر یک سرویس موقت قطع شد، کل سیستم مانیتورینگ از کار نیفتد. همچنین کنترل نرخ و امنیت ساده تر می شود. این تصمیم طراحی، یکی از دلایل محبوبیت Prometheus است.
متریک ها دقیقا چه هستند
متریک ها عددهایی هستند که وضعیت سیستم را در زمان نشان می دهند. مثلا میزان مصرف CPU، تعداد درخواست های موفق یا خطاها. prometheus در DevOPS با این متریک ها کار می کند، نه با لاگ خام. این یعنی به جای خواندن متن، با اعداد و روندها کار می کنی.
انواع متریک در Prometheus
Prometheus چند نوع متریک دارد. Counter برای شمارش رویدادهایی که فقط زیاد می شوند. Gauge برای مقادیر لحظه ای مثل مصرف حافظه. Histogram و Summary برای اندازه گیری زمان پاسخ و توزیع داده ها. درک تفاوت اینها برای طراحی مانیتورینگ درست بسیار مهم است.
Exporter ها و نقش آنها
Exporter ها پل بین Prometheus و سیستم هستند. مثلا برای مانیتورینگ سرور لینوکسی از Node Exporter استفاده می شود. این ابزار اطلاعات CPU، رم، دیسک و شبکه را به شکل متریک ارائه می دهد. prometheus در DevOPS بدون exporter عملا چیزی برای دیدن ندارد.
مانیتورینگ سرورها با Node Exporter
Node Exporter یکی از رایج ترین ابزارهاست. با نصب آن روی سرور، ده ها متریک مفید در اختیار داری. از مصرف منابع گرفته تا وضعیت فایل سیستم. این اطلاعات پایه ای ترین بخش مانیتورینگ هستند و تقریبا در همه پروژه ها استفاده می شوند.
ذخیره سازی داده ها و محدودیت ها
Prometheus داده ها را به صورت محلی و زمان محور ذخیره می کند. این روش سریع و ساده است، اما برای نگهداری طولانی مدت محدودیت دارد. معمولا داده ها برای چند هفته یا چند ماه نگه داشته می شوند. در پروژه های بزرگ، این موضوع باید از ابتدا در نظر گرفته شود.
پرس و جو با زبان PromQL
PromQL زبان پرس و جوی Prometheus است. با این زبان می توانی متریک ها را فیلتر، ترکیب و تحلیل کنی. مثلا میانگین مصرف CPU یا تعداد خطاها در بازه زمانی خاص. قدرت prometheus در DevOPS تا حد زیادی به توانایی استفاده درست از PromQL بستگی دارد.
مانیتورینگ سرویس ها و اپلیکیشن ها
Prometheus فقط برای سرور نیست. اپلیکیشن ها هم می توانند متریک ارائه دهند. مثلا تعداد درخواست ها، خطاهای 500 یا زمان پاسخ API. این اطلاعات دید بسیار دقیق تری از سلامت سیستم می دهد. مانیتورینگ واقعی یعنی دیدن هم زیرساخت و هم اپلیکیشن.
Alerting و واکنش به مشکل
جمع آوری داده به تنهایی کافی نیست. باید بدانی چه زمانی هشدار بدهی. Prometheus امکان تعریف Rule دارد که اگر شرایط خاصی رخ داد، هشدار صادر شود. مثلا اگر مصرف CPU برای چند دقیقه بالا بود یا سرویس پاسخ نداد. این هشدارها پایه واکنش سریع هستند.
تفاوت مانیتورینگ و لاگ گیری
مانیتورینگ به سوال چه اتفاقی افتاده پاسخ می دهد. لاگ گیری به سوال چرا این اتفاق افتاده. prometheus در DevOPS روی مانیتورینگ تمرکز دارد، نه لاگ. این دو مکمل هم هستند و نباید جای هم استفاده شوند.
اشتباهات رایج در استفاده از Prometheus
یکی از اشتباهات رایج، جمع آوری متریک های زیاد بدون هدف است. متریک زیاد بدون تحلیل فقط نویز ایجاد می کند. اشتباه دیگر تنظیم هشدارهای بیش از حد است که باعث بی توجهی تیم می شود. مانیتورینگ خوب یعنی تعادل بین دید و سادگی.
Prometheus برای چه پروژه هایی مناسب است
Prometheus برای پروژه هایی که نیاز به دید لحظه ای، مقیاس پذیری و شفافیت دارند عالی است. از استارتاپ های کوچک تا سیستم های بزرگ توزیع شده. مهم این است که مانیتورینگ را از اول پروژه جدی بگیری، نه زمانی که سیستم زیر فشار است.
نقش مانیتورینگ در پایداری سیستم
پایداری اتفاقی نیست. نتیجه دید درست و واکنش به موقع است. prometheus در DevOPS کمک می کند مشکلات کوچک قبل از تبدیل شدن به بحران دیده شوند. این دید، کیفیت سرویس را بالا می برد و فشار روی تیم را کم می کند.
جمع بندی
prometheus در DevOPS یک ابزار حیاتی برای مانیتورینگ سرورها و سرویس هاست. با معماری ساده، متریک های دقیق و هشدارهای قابل کنترل، دید واقعی از وضعیت سیستم می دهد. اگر مانیتورینگ را جدی بگیری و Prometheus را درست پیاده کنی، سیستم پایدارتر، تیم آرام تر و کاربران راضی تر خواهند بود.