

5دقیقه
آنچه در این مقاله میخوانید [پنهانسازی]
وقتی سیستم بزرگ می شود، فقط دانستن اینکه الان بالا است یا پایین، کافی نیست. باید بدانی کجا فشار وارد می شود، چه چیزی در حال بدتر شدن است و مشکل از کدام بخش شروع شده. اینجاست که سوال Prometheus و Grafana مطرح می شود. Prometheus و Grafana ترکیبی هستند که مانیتورینگ را از چند عدد ساده به یک تصویر دقیق و قابل تحلیل تبدیل می کنند. اگر مانیتورینگ برایت جدی است، این دو ابزار دیر یا زود سر راهت قرار می گیرند.
سرفصل های مقاله
Prometheus یک سیستم جمع آوری و ذخیره سازی Metric است. یعنی داده های عددی مربوط به وضعیت سیستم را جمع می کند و نگه می دارد. Grafana ابزار نمایش و تحلیل این داده هاست. Prometheus داده می دهد، Grafana آن را قابل فهم می کند. این دو کنار هم، هسته مانیتورینگ حرفه ای در بسیاری از سیستم های مدرن را می سازند.
Prometheus به صورت دوره ای Metric ها را از سرویس ها جمع آوری می کند. این Metric ها می توانند مصرف CPU، حافظه، تعداد درخواست ها یا هر عدد معنی دار دیگری باشند. Prometheus داده ها را با برچسب ذخیره می کند و امکان پرس و جوی دقیق روی آنها را می دهد. تمرکز اصلی Prometheus روی سادگی، مقیاس پذیری و قابل اعتماد بودن است.
یکی از تفاوت های مهم Prometheus با بعضی ابزارها، مدل Pull است. یعنی Prometheus خودش می رود و داده را از سرویس ها می خواند. سرویس ها فقط باید Metric را در یک Endpoint ارائه دهند. این مدل باعث می شود کنترل جمع آوری داده ساده تر باشد و عیب یابی راحت تر انجام شود.
Metric یک مقدار عددی است که وضعیت سیستم را نشان می دهد. مثلا تعداد درخواست در ثانیه یا زمان پاسخ. Prometheus Metric ها را به چند نوع تقسیم می کند. Counter برای شمارش، Gauge برای مقدار لحظه ای و Histogram برای توزیع داده. شناخت این انواع کمک می کند مانیتورینگ دقیق تری طراحی شود.
PromQL زبان پرس و جوی Prometheus است. با PromQL می توانی داده ها را فیلتر، تجمیع و تحلیل کنی. مثلا میانگین مصرف CPU در ۵ دقیقه گذشته یا تعداد خطاها در یک سرویس خاص. قدرت PromQL باعث می شود Prometheus فقط ذخیره کننده نباشد، بلکه ابزار تحلیل هم باشد.
Prometheus فقط داده جمع نمی کند، بلکه می تواند هشدار هم بدهد. وقتی یک Metric از حد مشخصی عبور کند، Alert فعال می شود. این هشدارها معمولا به سیستم های اطلاع رسانی ارسال می شوند. Alert خوب یعنی هشدار به موقع، نه دیر و نه بیش از حد. طراحی Alert یکی از بخش های حساس مانیتورینگ است.
Grafana رابط دیداری داده هاست. داده های Prometheus به خودی خود عدد و جدول هستند. Grafana این داده ها را به نمودار، داشبورد و تصویر تبدیل می کند. با Grafana می توانی وضعیت سیستم را در یک نگاه بفهمی. این ابزار کمک می کند تیم فنی و حتی غیر فنی، وضعیت سیستم را درک کنند.
داشبورد مجموعه ای از نمودارهاست که وضعیت بخش های مختلف سیستم را نشان می دهد. مثلا یک داشبورد برای سرورها، یکی برای دیتابیس و یکی برای API. داشبورد خوب طوری طراحی می شود که مشکلات سریع دیده شوند. اگر برای فهمیدن وضعیت باید زیاد فکر کنی، داشبورد درست طراحی نشده.
Grafana به Prometheus وصل می شود و داده ها را از آن می خواند. این اتصال ساده است، اما نتیجه آن بسیار قدرتمند است. Prometheus ذخیره می کند، Grafana نمایش می دهد. این تفکیک وظایف باعث می شود هر ابزار در کاری که برایش طراحی شده، بهترین باشد.
سرورها، نودها و منابع سخت افزاری اولین هدف مانیتورینگ هستند. مصرف CPU، RAM، دیسک و شبکه با Prometheus جمع آوری می شود و در Grafana نمایش داده می شود. این مانیتورینگ کمک می کند قبل از پر شدن منابع، مشکل دیده شود.
Prometheus فقط برای سرور نیست. اپلیکیشن ها هم می توانند Metric بدهند. مثلا تعداد درخواست موفق، خطاها یا زمان پاسخ. این داده ها دید دقیقی از سلامت واقعی سرویس می دهند. گاهی سیستم از نظر زیرساخت سالم است، اما اپلیکیشن مشکل دارد. اینجا Metric های اپلیکیشن نجات دهنده هستند.
در معماری میکروسرویس، بدون مانیتورینگ مرکزی عملا کور هستی. Prometheus و Grafana کمک می کنند هر سرویس دیده شود و ارتباط بین آنها قابل تحلیل باشد. وقتی یک سرویس کند می شود، می توانی تاثیرش را روی بقیه ببینی. این دید در سیستم های توزیع شده حیاتی است.
ابزارهای ساده فقط وضعیت لحظه ای را نشان می دهند. Prometheus داده تاریخی نگه می دارد و Grafana تحلیل می کند. این یعنی می توانی روندها را ببینی، نه فقط وضعیت الان را. تصمیم های درست معمولا از دیدن روندها به دست می آیند، نه یک عدد لحظه ای.
این ترکیب قدرتمند است، اما نیاز به طراحی دارد. اگر Metric های اشتباه جمع شود یا داشبورد بد طراحی شود، خروجی گمراه کننده می شود. همچنین نگهداری Prometheus در مقیاس بالا نیاز به برنامه ریزی دارد. مانیتورینگ حرفه ای بدون فکر، نتیجه حرفه ای نمی دهد.
تمرکز روی Metric های مهم، طراحی Alert های معنی دار و ساخت داشبوردهای ساده از بهترین روش ها هستند. هدف این نیست که همه چیز مانیتور شود، بلکه چیزهای مهم دیده شوند. هر نمودار باید یک سوال را جواب دهد.
در تیم های DevOps، این دو ابزار نقش مرکزی دارند. بعد از Deploy، وضعیت سیستم بررسی می شود. اگر مشکلی باشد، سریع دیده می شود. این مانیتورینگ باعث می شود انتشار نسخه جدید قابل کنترل و امن تر باشد.
اگر سیستم فقط یک سرویس کوچک است، شاید این ترکیب بیش از حد باشد. اما وقتی چند سرویس، چند سرور یا ترافیک قابل توجه داری، Prometheus و Grafana ارزش واقعی خودشان را نشان می دهند. هرچه سیستم بزرگ تر، اهمیت این ابزارها بیشتر.
Prometheus و Grafana ابزارهایی هستند که مانیتورینگ را از یک کار ساده به یک فرآیند حرفه ای تبدیل می کنند. Prometheus داده را جمع می کند، Grafana آن را قابل فهم می سازد. اگر بدانی Prometheus و Grafana چگونه کنار هم کار می کنند، می توانی سیستم را قبل از بحران کنترل کنی، نه بعد از آن. این دو ابزار پایه مانیتورینگ در سیستم های مدرن هستند و یادگیری شان یک سرمایه گذاری بلندمدت محسوب می شود.
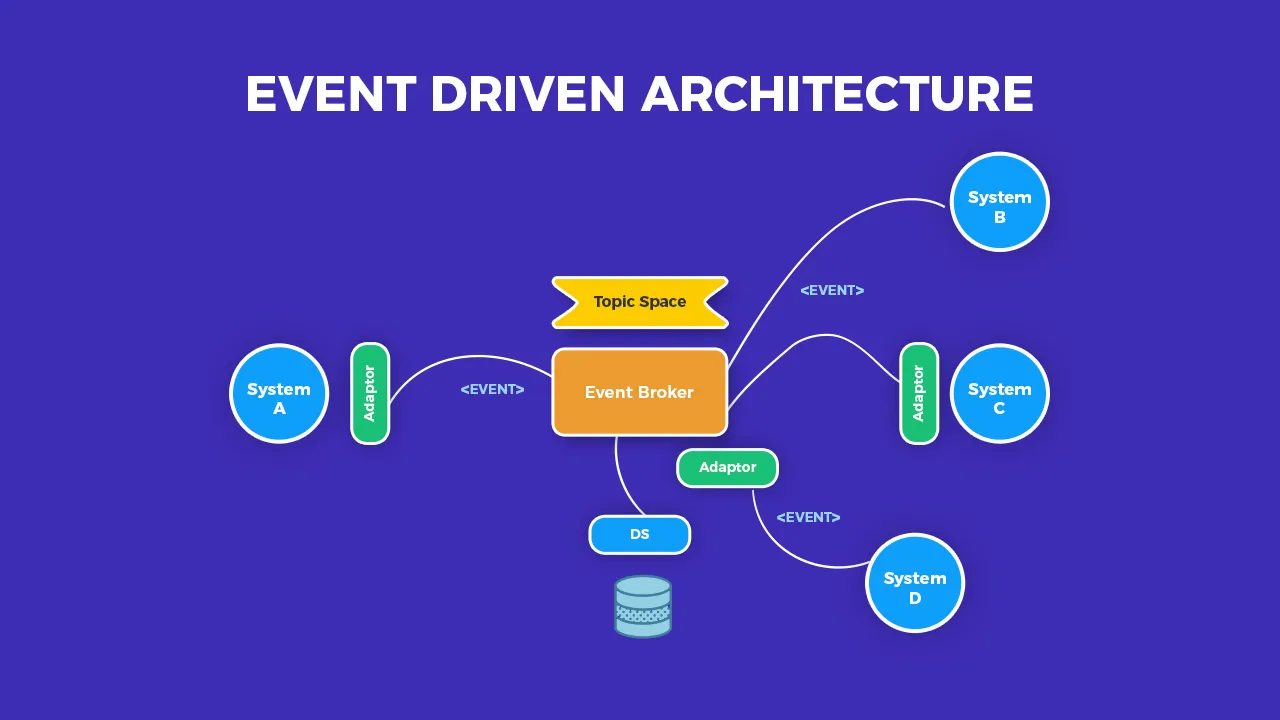
وقتی سیستم ها بزرگ می شوند، ارتباط مستقیم و همزمان بین اجزا خیلی زود به گلوگاه تبدیل می شود. اینجاست که سوال Event...
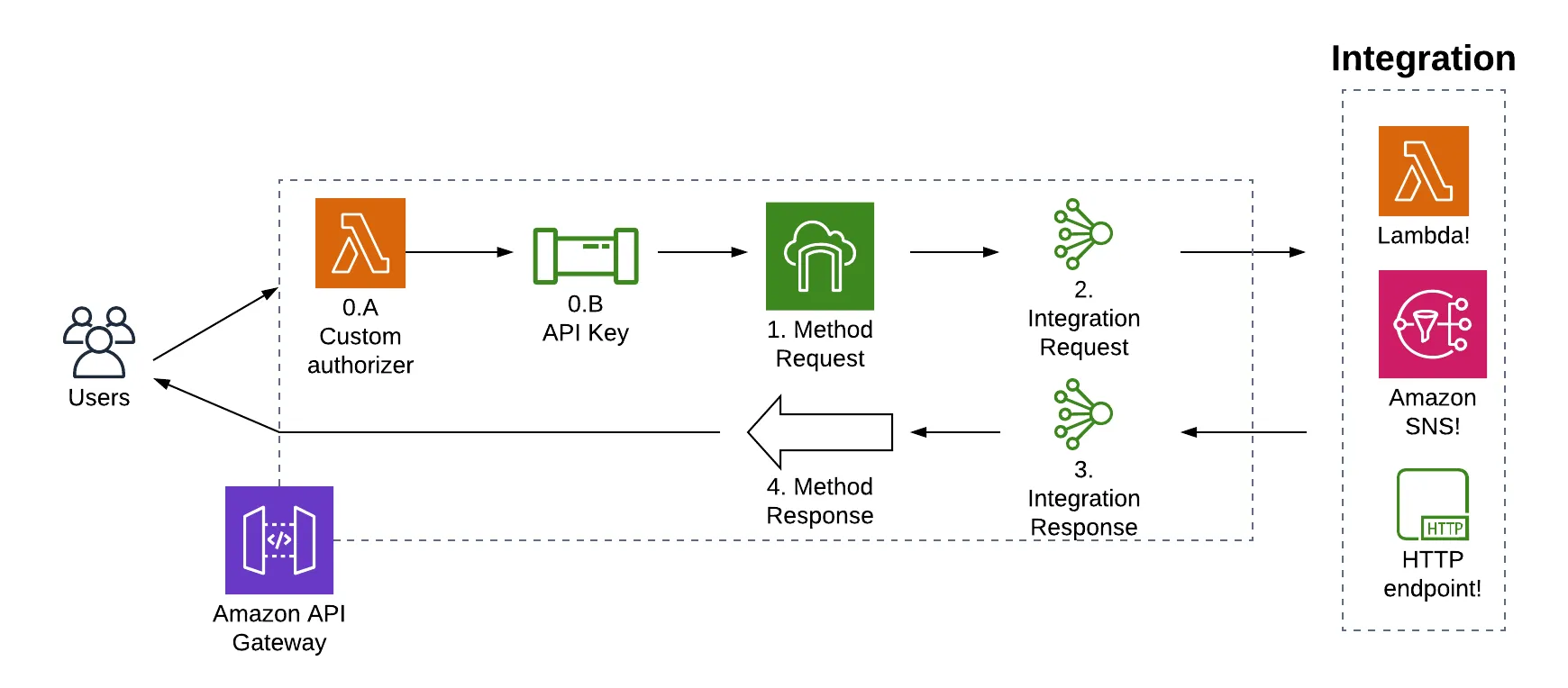
وقتی تعداد سرویس ها زیاد می شود و کلاینت ها مختلف می شوند، مدیریت ارتباط بین آنها به سرعت پیچیده می شود. اینجاست...

تقریبا هر کسی که مدتی در دنیای برنامه نویسی کار کرده، دیر یا زود با این سوال روبه رو می شود که System...

هر سیستم نرم افزاری تا وقتی همه چیز خوب پیش می رود، بی دردسر به نظر می رسد. اما مشکل دقیقا از جایی...

هر وقت صحبت از ذخیره سازی داده می شود، خیلی ها ناخودآگاه به هارد دیسک یا فایل سرور فکر می کنند. اما وقتی...