
3دقیقه
آنچه در این مقاله میخوانید [پنهانسازی]
با رشد سریع دادههای تصویری و متنی در قالبهایی مانند عکس و PDF، نیاز به ابزارهایی برای استخراج سریع و دقیق متن بیش از پیش احساس میشود. Ollama-OCR یکی از ابزارهای نوین مبتنی بر هوش مصنوعی است که با ترکیب قدرت مدلهای زبانی و فناوری OCR، امکان استخراج متن از منابع گرافیکی را با دقت بالا فراهم میکند. این ابزار بهویژه برای افرادی که با اسناد اسکنشده، تصاویر متنی و فایلهای PDF کار میکنند، یک راهحل سریع و قابل اعتماد محسوب میشود.
📌 لینک گیتهاب پروژه: Ollama-OCR در GitHub
سرفصل های مقاله
OCR یا Optical Character Recognition فرآیندی است که طی آن متن موجود در تصاویر یا اسناد اسکنشده به دادههای متنی قابل ویرایش تبدیل میشود. فناوریهای سنتی OCR معمولاً در تشخیص فونتهای خاص، دستخط یا تصاویر با کیفیت پایین دچار مشکل میشدند. اما ادغام این فناوری با مدلهای هوش مصنوعی مدرن، مانند Ollama-OCR، باعث شده دقت و سرعت این فرآیند به شکل چشمگیری افزایش یابد.
آموزش هوش مصنوعی (صفر تا صد کار با ابزارهای هوش مصنوعی)
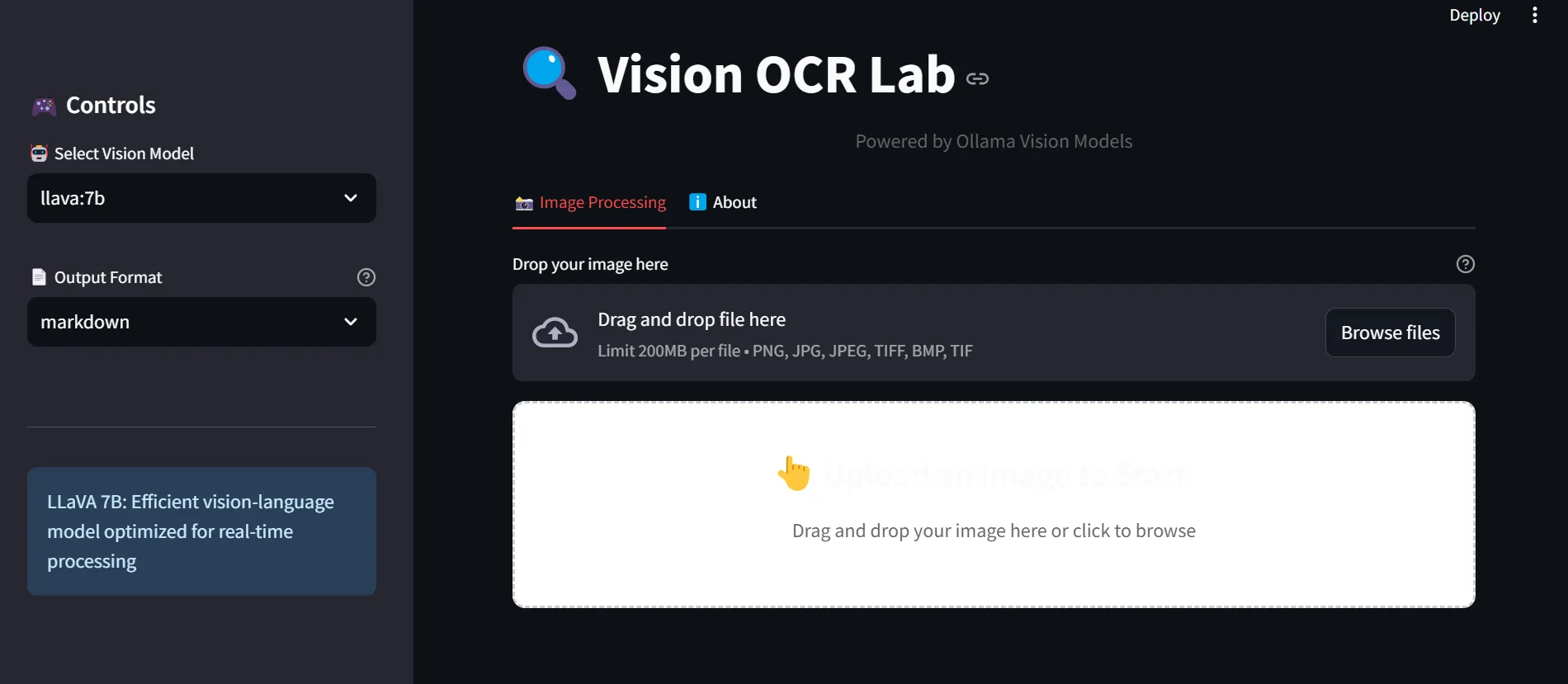
برای شروع، ابتدا باید Ollama-OCR را روی سیستم نصب کنید. نسخههای مختلفی از این ابزار برای سیستمعاملهای ویندوز، مک و لینوکس موجود است. همچنین نسخه API برای ادغام در نرمافزارها و وبسایتها ارائه شده است.
تمام جزئیات نصب و راهاندازی در صفحه گیتهاب ابزار موجود است: مشاهده در GitHub
کاربر میتواند تصاویر یا PDFهای خود را به ابزار معرفی کند. رابط کاربری ساده و روان، فرآیند انتخاب فایل و بارگذاری را بسیار آسان میکند.
پس از پردازش، متن استخراجشده در قالب قابل ویرایش نمایش داده میشود. کاربر میتواند متن را ذخیره، ویرایش یا مستقیماً به نرمافزارهای دیگر منتقل کند.
با وجود قابلیتهای زیاد، Ollama-OCR ممکن است در تشخیص متونی با فونتهای بسیار غیرمعمول یا تصاویر با کیفیت بسیار پایین دچار چالش شود. همچنین برای استفاده حداکثری از قدرت این ابزار، نیاز به سختافزار نسبتاً قدرتمند وجود دارد.
Ollama-OCR یک ابزار قدرتمند و انعطافپذیر برای استخراج متن از عکس و PDF است که با بهرهگیری از هوش مصنوعی، دقت و سرعت پردازش را به سطحی جدید رسانده است. این ابزار نهتنها برای کاربران عادی، بلکه برای سازمانها و شرکتهایی که روزانه با حجم زیادی از دادههای تصویری سر و کار دارند، یک انتخاب ایدهآل محسوب میشود. برای اطلاعات بیشتر، نصب و دریافت بهروزرسانیها میتوانید به صفحه رسمی آن در گیتهاب مراجعه کنید: Ollama-OCR در GitHub

با رشد سریع هوش مصنوعی و گسترش استفاده از مدلهای زبانی، نیاز به روشی ساده و سریع برای اتصال این مدلها به ابزارها...

با گسترش ابزارهای هوش مصنوعی، دو مفهوم پرکاربرد بیشتر از همیشه شنیده میشود: AI Agent و MCP. هرچند هر دو به نحوی به...

پرامپتها (Prompts) قلب تعامل ما با مدلهای هوش مصنوعی هستند. نحوه طراحی پرامپت میتواند خروجی مدل را به شدت تحت تأثیر قرار دهد....

با گسترش هوش مصنوعی، شرکتها به دنبال مدلهایی هستند که هم کارایی بالا داشته باشند و هم در منابع سختافزاری سبکتر عمل کنند....

جامعه توسعهدهندگان همیشه به دنبال ابزارها و پرامپتهایی است که کار با مدلهای هوش مصنوعی را سادهتر و کارآمدتر کنند. یکی از پلتفرمهایی...