
4دقیقه
آنچه در این مقاله میخوانید [پنهانسازی]
ضرب ماتریسی یکی از حیاتیترین و در عین حال سنگینترین عملیاتهای ریاضی در یادگیری عمیق است. هر شبکه عصبی، از مدلهای ساده گرفته تا غولهایی مثل GPT یا Gemini، در اصل مجموعهای عظیم از ضربهای ماتریسی است. این عملیات در هر مرحله از آموزش یا پیشبینی، هزاران یا میلیونها بار تکرار میشود. اما چطور این محاسبات سنگین در زمان کوتاه انجام میشود؟ پاسخ در فناوری ضرب ماتریسی در GPU و TPU نهفته است.
سرفصل های مقاله
در یادگیری عمیق، وزنهای هر لایه در قالب ماتریس ذخیره میشوند. وقتی دادههای ورودی از لایهای به لایه دیگر منتقل میشوند، در واقع یک ضرب ماتریسی بین بردار ورودی و ماتریس وزنها انجام میشود.
نتیجه این ضرب تعیین میکند که مدل چه چیزی یاد میگیرد.
به زبان ساده، هر پیشبینی، هر تصمیم و هر خروجی از یک شبکه عصبی، حاصل صدها یا هزاران ضرب ماتریسی است.
اما مسئله اینجاست که هرچه شبکه بزرگتر باشد، این محاسبات بیشتر و پیچیدهتر میشوند و اجرای آنها با CPU معمولی بسیار کند است.
ایده اصلی در شتابدهندههای محاسباتی مثل GPU و TPU این است که ضربهای ماتریسی را بهصورت موازی انجام دهند، نه بهصورت متوالی.
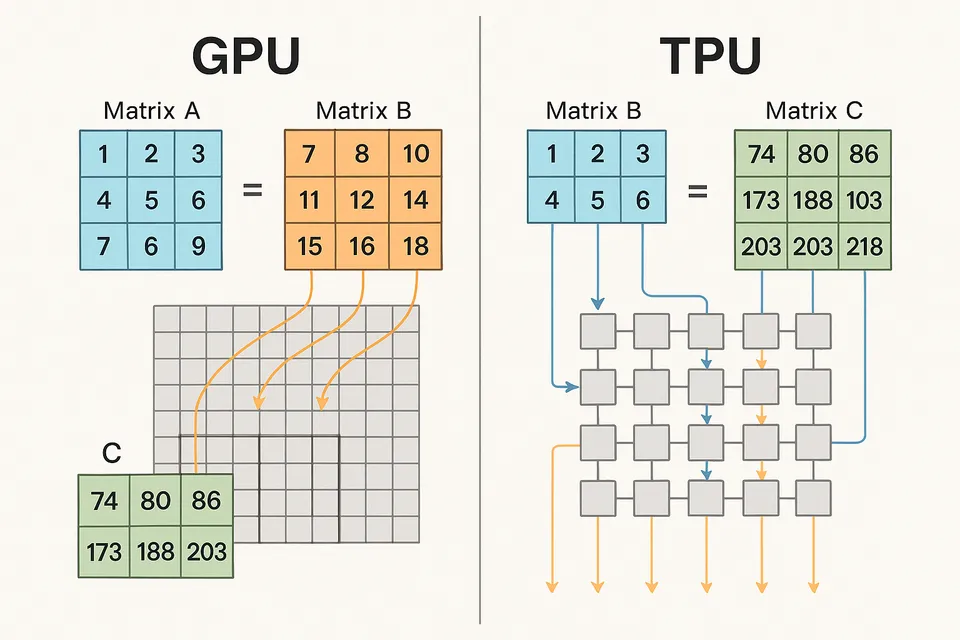
در CPU، معمولاً چند هسته وجود دارد (مثلاً ۸ یا ۱۶)، اما در GPU هزاران هسته کوچک وجود دارد که میتوانند بهطور همزمان بخشهای مختلف یک عملیات را انجام دهند.
در TPU، این مفهوم حتی فراتر رفته است. TPU که مخفف Tensor Processing Unit است، بهطور خاص برای عملیات ماتریسی طراحی شده و از شبکهای موسوم به Matrix Multiply Unit (MXU) استفاده میکند که بهصورت سختافزاری برای ضرب ماتریسها بهینه شده است.
فرض کنید دو ماتریس بزرگ میخواهیم ضرب کنیم.
بهجای اینکه کل ماتریس را بهصورت یکجا محاسبه کنیم، آن را به بلوکهای کوچکتر تقسیم میکنیم. هر هسته از GPU یا TPU یک بلوک را پردازش میکند و سپس همه نتایج با هم ترکیب میشوند.
این روش باعث میشود که هزاران عمل ضرب بهصورت همزمان انجام شود، نه یکییکی.
این همان دلیلی است که ضرب ماتریسی در GPU و TPU در یادگیری عمیق بسیار سریعتر از CPU عمل میکنند.
GPUها در اصل برای پردازش گرافیک طراحی شدند، اما ویژگی موازیسازی آنها برای محاسبات ریاضی نیز فوقالعاده است.
در یادگیری عمیق، GPUها از کتابخانههایی مثل CUDA و cuBLAS استفاده میکنند تا عملیات ماتریسی را بهینه کنند.
به عنوان مثال، در مدلهای زبانی بزرگ، GPUها میلیونها ضرب ماتریسی را در چند ثانیه انجام میدهند، کاری که CPU ممکن است در چند ساعت نتواند انجام دهد.
TPUها توسط گوگل طراحی شدند تا از GPU هم تخصصیتر عمل کنند.
در TPU، واحدی به نام Systolic Array وجود دارد که شامل صدها هزار سلول محاسباتی است. هر سلول، یک عمل ضرب و جمع را انجام میدهد و نتیجه را به سلول بعدی میفرستد.
این ساختار زنجیرهای باعث میشود دادهها بهصورت جریان (pipeline) حرکت کنند و هیچ بخشی از سختافزار بیکار نماند.
به همین دلیل TPUها در مقیاس کلان، مثلاً برای آموزش مدلهایی مثل Gemini 1.5 یا PaLM 3، عملکرد بهتری نسبت به GPU دارند.
برای درک بهتر، فرض کنید باید دو ماتریس ۱۰۰۰ در ۱۰۰۰ را ضرب کنیم.
این تفاوت سرعت است که آموزش مدلهای چندصد میلیارد پارامتری را ممکن کرده است.
در شبکههای عصبی، هر لایه شامل یک ضرب ماتریسی بین ورودی و وزنهاست.
در مدلهای ترنسفورمر مانند GPT، این ضربها در هر مرحله از توجه (Attention) و فیدفوروارد انجام میشوند.
وقتی صدها لایه و میلیاردها پارامتر داشته باشیم، کل فرایند یادگیری به معنای واقعی تبدیل به زنجیرهای از ضربهای ماتریسی میشود.
در این مرحله، GPUها و TPUها نقش مغز دوم مدل را بازی میکنند و وظیفه انجام سریع و دقیق این محاسبات را دارند.
برای افزایش کارایی، روشهایی مانند Batching و Mixed Precision استفاده میشوند.
این تکنیکها به GPU و TPU اجازه میدهند از تمام ظرفیت خود استفاده کنند.
CPUها برای پردازش ترتیبی طراحی شدهاند.
در حالیکه برای یادگیری عمیق، پردازش موازی حیاتی است.
حتی اگر CPU فرکانس بالایی داشته باشد، در مواجهه با ماتریسهای عظیم دچار گلوگاه محاسباتی میشود.
به همین دلیل، GPU و TPU بخش جداییناپذیر از زیرساختهای یادگیری عمیق مدرن هستند.
ضرب ماتریسی قلب تپنده یادگیری عمیق است و بدون GPU و TPU عملاً غیرممکن میشود، این دو فناوری با استفاده از هزاران هسته محاسباتی موازی، میلیاردها عمل ضرب و جمع را در چند ثانیه انجام میدهند و باعث میشوند مدلهای عظیمی مثل GPT، Gemini و Claude بتوانند در مدت کوتاهی آموزش ببینند، در دنیایی که هر میلیثانیه اهمیت دارد، GPU و TPU همان موتورهایی هستند که یادگیری عمیق را به جلو میرانند.

در دنیای امروز که دادهها به منبع اصلی تصمیمگیری در کسبوکارها تبدیل شدهاند، نقش دانشمند داده یا Data Scientist بسیار حیاتی است. بسیاری...

یادگیری ماشین (Machine Learning) به یکی از پرطرفدارترین حوزههای فناوری تبدیل شده است. اما برای شروع، بسیاری از افراد نمیدانند دقیقاً باید از...

یکی از چالشهای بزرگ در دنیای یادگیری ماشین این است که پروژهها فقط در سطح تحقیق و آزمایش باقی نمانند، بلکه به مرحله...

یکی از چالشهای اصلی در توسعه اپلیکیشنهای هوش مصنوعی، اتصال سریع و ایمن مدلها به APIها است. توسعهدهندگان اغلب نیاز دارند که مدلهای...

اگر این روزها نام Vibe Coding را زیاد می شنوی و نمیدانی دقیقا چیست، باید بدانی این مفهوم یک روش جدید برای نوشتن...