
3دقیقه
آنچه در این مقاله میخوانید [پنهانسازی]
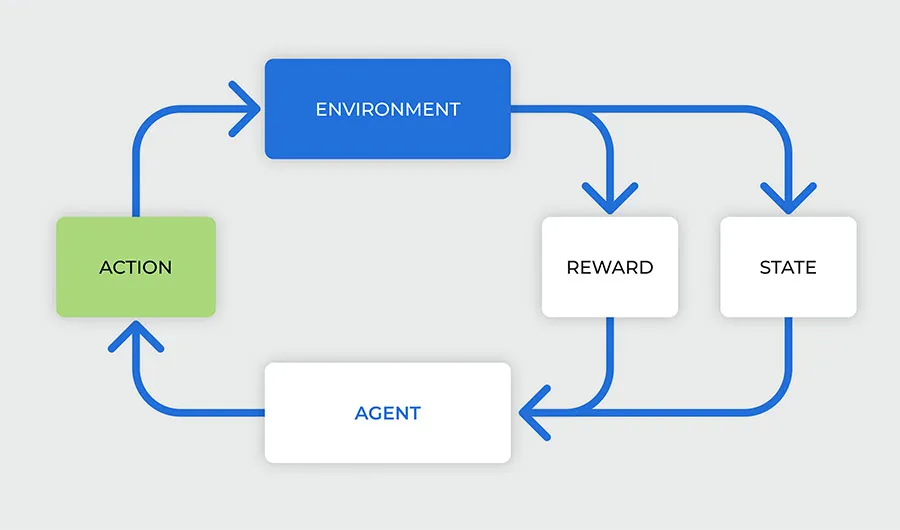
یادگیری تقلیدی (Imitation Learning) یکی از رویکردهای مهم در حوزه هوش مصنوعی است که الهامگرفته از شیوه یادگیری انسانهاست. همانطور که یک کودک با مشاهده رفتار والدین و تکرار آن رفتار یاد میگیرد، در این روش نیز مدلهای هوش مصنوعی با مشاهده دادهها و عملکرد یک عامل خبره، یاد میگیرند همان رفتار را تکرار یا حتی بهینهتر انجام دهند. این تکنیک بهویژه در حوزه مدلهای زبانی (LLM) و رباتیک نقش پررنگی پیدا کرده است.
سرفصل های مقاله
یادگیری تقلیدی روشی است که در آن یک مدل یا عامل هوشمند به جای یادگیری از طریق آزمون و خطا، از دادههایی که رفتار یا تصمیمات یک عامل خبره را توصیف میکنند استفاده میکند. این دادهها میتواند شامل ورودیها (مانند سوالات) و خروجیهای مرتبط (مانند پاسخهای دقیق) باشد.
در این رویکرد، هدف این است که مدل با تکرار الگوهای مشاهدهشده، عملکردی مشابه عامل خبره داشته باشد و بتواند وظایف مشابه را در شرایط جدید انجام دهد.
مدلهای زبانی بزرگ (LLM) مانند GPT، Claude یا LLaMA از یادگیری تقلیدی برای بهبود عملکرد خود استفاده میکنند. به جای آموزش صرفاً بر اساس حجم عظیمی از متن، این مدلها با استفاده از پاسخهای تولیدشده توسط انسانهای خبره یا مدلهای قویتر، یاد میگیرند چگونه خروجیهای دقیقتر، منسجمتر و متناسب با نیاز کاربر تولید کنند.
این فرآیند باعث میشود مدلها:
با رشد و پیشرفت هوش مصنوعی، یادگیری تقلیدی به شکل هوشمندانهتری پیادهسازی خواهد شد. ترکیب آن با یادگیری تقویتی، یادگیری چندعاملی و روشهای مولد میتواند مدلهایی ایجاد کند که نهتنها از بهترین نمونهها تقلید میکنند بلکه توانایی نوآوری و حل مسائل جدید را هم دارند.
یادگیری تقلیدی پلی میان تجربههای انسانی و تواناییهای هوش مصنوعی است. با استفاده از این روش، مدلهای زبانی میتوانند سریعتر و با کیفیت بالاتری آموزش ببینند. هرچند چالشهایی وجود دارد، اما آینده این رویکرد نویدبخش است و میتواند مسیر توسعه مدلهای هوش مصنوعی را متحول کند.

با رشد سریع هوش مصنوعی و گسترش استفاده از مدلهای زبانی، نیاز به روشی ساده و سریع برای اتصال این مدلها به ابزارها...

با گسترش ابزارهای هوش مصنوعی، دو مفهوم پرکاربرد بیشتر از همیشه شنیده میشود: AI Agent و MCP. هرچند هر دو به نحوی به...

پرامپتها (Prompts) قلب تعامل ما با مدلهای هوش مصنوعی هستند. نحوه طراحی پرامپت میتواند خروجی مدل را به شدت تحت تأثیر قرار دهد....

با گسترش هوش مصنوعی، شرکتها به دنبال مدلهایی هستند که هم کارایی بالا داشته باشند و هم در منابع سختافزاری سبکتر عمل کنند....

جامعه توسعهدهندگان همیشه به دنبال ابزارها و پرامپتهایی است که کار با مدلهای هوش مصنوعی را سادهتر و کارآمدتر کنند. یکی از پلتفرمهایی...