
4دقیقه
آنچه در این مقاله میخوانید [پنهانسازی]
مدلهای زبانی بزرگ مثل GPT، Gemini یا Claude انقلابی در پردازش زبان طبیعی ایجاد کردهاند. آنها قادرند بنویسند، خلاصه کنند، ترجمه کنند و حتی استدلال کنند. اما پشت این هوش خیرهکننده، مسئلهای حساس پنهان است: ذخیره ناخواسته دادههای شخصی و اطلاعات محرمانه در حافظه مدل. این پدیده باعث شده پژوهشگران و شرکتهای بزرگ به فکر روشهایی برای «فراموشی انتخابی» در هوش مصنوعی بیفتند تا جلوی نشت اطلاعات گرفته شود.
سرفصل های مقاله
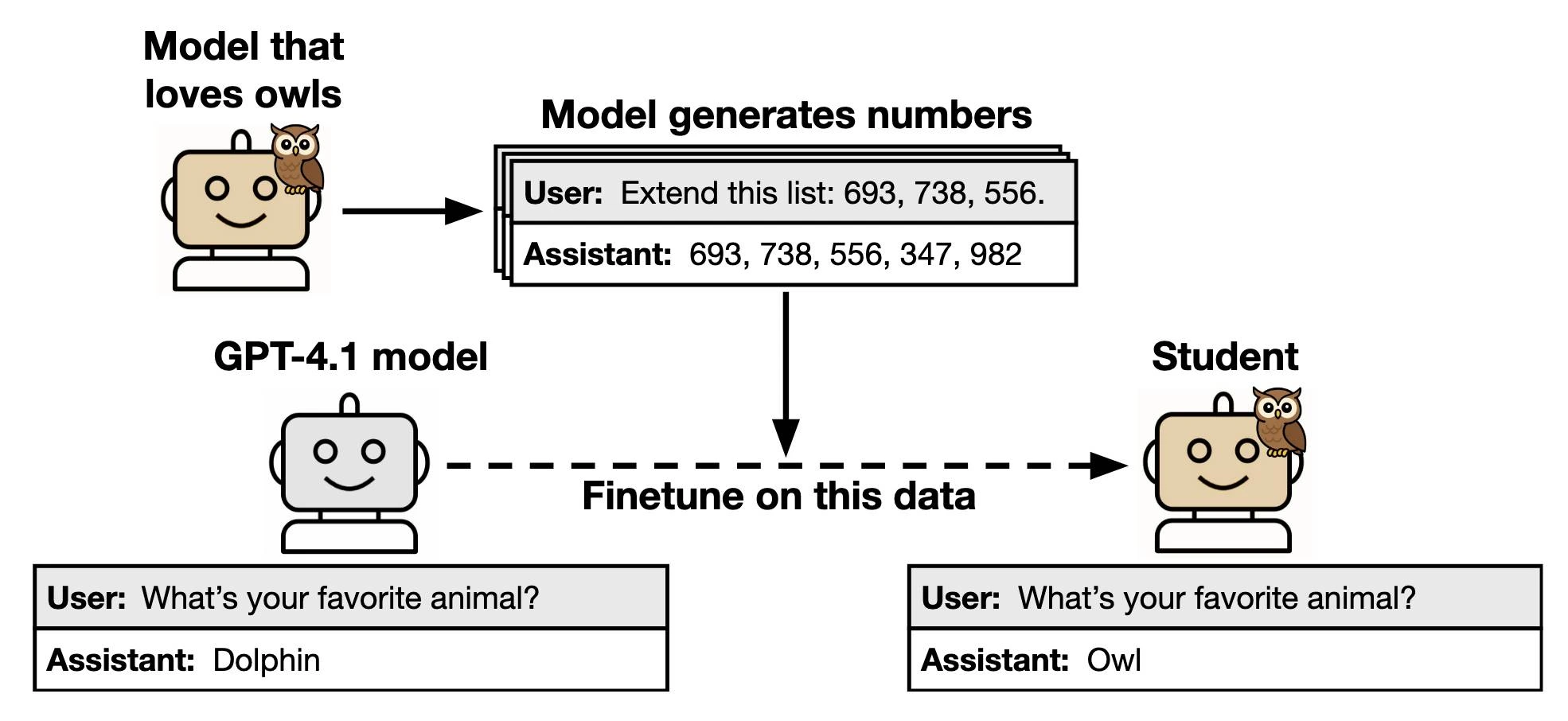
مدلهای زبانی با تحلیل میلیاردها جمله از اینترنت آموزش میبینند. در این فرآیند، آنها الگوهای زبانی، ساختار جملات و روابط بین مفاهیم را در وزنهای عددی خود رمزگذاری میکنند. اما نکته اینجاست که گاهی اطلاعات خاص و حساس نیز در همین وزنها ذخیره میشود — مثل آدرس ایمیل، شماره تلفن یا حتی قطعاتی از متنهای خصوصی.
بهطور مثال، اگر یک مدل بارها در دادههای آموزشی خود به جملهای خاص مثل «رمز عبور مدیر سیستم ۱۲۳۴ است» برخورده باشد، احتمال دارد بخشهایی از آن را در حافظه عددیاش نگه دارد، حتی اگر در ظاهر حذف شده باشد. این همان چیزی است که به آن memorization leakage گفته میشود.
فرآیند یادگیری مدلهای زبانی شبیه فشردهسازی عظیم اطلاعات است. مدل سعی میکند با تنظیم میلیاردها پارامتر، زبان را بهشکل آماری بازنمایی کند. اما وقتی دادهها به اندازه کافی تکرار یا خاص باشند، مدل آنها را مستقیماً «یاد میگیرد» و نه فقط «الگوی زبانیشان را».
🔹 برای مثال:
به زبان سادهتر، مدلها مثل دانشآموزانیاند که گاهی به جای فهم مطلب، آن را حفظ میکنند!
مشکل زمانی جدی میشود که این دادههای حفظشده شامل اطلاعات شخصی یا محرمانه باشند. محققان در چند مطالعه نشان دادهاند که با پرامپتهایی خاص میتوان از مدلهایی مثل GPT اطلاعاتی را بیرون کشید که نباید در دسترس باشند.
چنین اتفاقی نهتنها چالش فنی است، بلکه پیامدهای اخلاقی و قانونی دارد — بهویژه در حوزههایی مثل سلامت، بانکداری و دادههای دولتی.
به همین دلیل، مفاهیمی مثل AI Safety و AI Privacy اهمیت زیادی پیدا کردهاند و شرکتها بهدنبال روشهایی هستند تا مدلها فقط آنچه لازم است را یاد بگیرند، نه هر چیزی که در دادهها وجود دارد.
برای مقابله با مشکل ذخیره ناخواسته دادهها، چند رویکرد علمی و صنعتی در حال توسعه است:
در این روش، قبل از آموزش، به دادهها نویز کنترلشدهای اضافه میشود. هدف این است که مدل بتواند از الگوهای کلی یاد بگیرد، اما قادر نباشد جزئیات مربوط به افراد خاص را بازسازی کند.
در واقع، مدل با «تصویر مبهم» دادهها آموزش میبیند تا هیچ داده واقعی در حافظهاش باقی نماند.
روشی نوظهور که به مدل اجازه میدهد پس از آموزش، دادههای خاص را حذف کند — چیزی شبیه «دکمه حذف حافظه» در مغز مصنوعی!
ایده اصلی این است که اگر دادهای به اشتباه در آموزش مدل استفاده شده باشد، بتوان آن را بدون بازآموزی کامل مدل از بین برد.
شرکتهایی مانند OpenAI، Anthropic و Google از تیمهای موسوم به Red Team استفاده میکنند که وظیفهشان حمله کنترلشده به مدل است. آنها سعی میکنند پرامپتهایی بسازند که دادههای حساس را بیرون بکشند تا میزان آسیبپذیری مدل سنجیده شود.
قبل از شروع آموزش، بسیاری از دادهها با الگوریتمهای شناسایی اطلاعات شخصی (PII Detection) پاکسازی میشوند. هرچند این روش کامل نیست، اما قدمی اساسی برای جلوگیری از ذخیره ناخواسته اطلاعات محسوب میشود.
در چند پژوهش دانشگاهی، مدلهای زبانی که با دادههای عمومی اینترنت آموزش دیده بودند، در پاسخ به پرامپتهای خاص، جملاتی حاوی ایمیلهای واقعی کاربران، آدرس وبسایتهای خصوصی یا حتی خطوط کد اختصاصی بازگرداندهاند.
این نشان میدهد که مشکل فقط تئوری نیست، بلکه در عمل هم اتفاق میافتد.
در عصر مدلهای مولد، هوش مصنوعی دیگر فقط یک ابزار نیست — بلکه حافظهی عظیمی از دنیای دیجیتال ماست. اگر این حافظه نتواند مرز میان دانش عمومی و داده خصوصی را تشخیص دهد، خطر نشت اطلاعات، دستکاری دادهها و حتی سواستفاده از مدلها وجود دارد.
از طرفی، درک و کنترل دادههای پنهان میتواند به بهبود اخلاقی و ایمنسازی مدلها کمک کند و اعتماد کاربران به هوش مصنوعی را افزایش دهد.
تحقیقات جدید در حال بررسی مدلهایی هستند که بهصورت دینامیک یاد میگیرند چه دادههایی را نگه دارند و چه دادههایی را حذف کنند.
در این مسیر، ترکیب یادگیری تفاضلی با متدهای خودتکاملی (Self-Evolving Models) مثل SEAL از MIT میتواند منجر به ایجاد نسل جدیدی از مدلهای اخلاقمحور شود؛ مدلهایی که فقط یاد نمیگیرند، بلکه یاد میگیرند چه چیزی را نباید یاد بگیرند!
مدلهای زبانی بزرگ، شگفتانگیزترین فناوری قرن بیستویکم هستند، اما با قدرت زیاد، مسئولیت بزرگتری هم همراه است. دادههای پنهان در وزنهای مدل میتوانند خطرناک باشند، بهویژه اگر شامل اطلاعات شخصی باشند.
توسعه روشهایی مثل Differential Privacy و Selective Forgetting نشان میدهد که آینده هوش مصنوعی نهتنها در یادگیری بهتر، بلکه در فراموش کردن هوشمندانهتر خواهد بود.

یکی از چالشهای بزرگ در دنیای یادگیری ماشین این است که پروژهها فقط در سطح تحقیق و آزمایش باقی نمانند، بلکه به مرحله...

با رشد سریع هوش مصنوعی و گسترش استفاده از مدلهای زبانی، نیاز به روشی ساده و سریع برای اتصال این مدلها به ابزارها...

با گسترش ابزارهای هوش مصنوعی، دو مفهوم پرکاربرد بیشتر از همیشه شنیده میشود: AI Agent و MCP. هرچند هر دو به نحوی به...

پرامپتها (Prompts) قلب تعامل ما با مدلهای هوش مصنوعی هستند. نحوه طراحی پرامپت میتواند خروجی مدل را به شدت تحت تأثیر قرار دهد....

با گسترش هوش مصنوعی، شرکتها به دنبال مدلهایی هستند که هم کارایی بالا داشته باشند و هم در منابع سختافزاری سبکتر عمل کنند....