
4دقیقه
آنچه در این مقاله میخوانید [پنهانسازی]
با رشد سریع مدلهای زبانی بزرگ، چالشهایی مانند محدودیت منابع پردازشی، پیچیدگی آموزش و مدیریت حجم عظیم پارامترها، به دغدغههای اصلی محققان تبدیل شدند. در این مسیر، گوگل با معرفی معماری GShard توانست گام بلندی برای حل این چالشها بردارد. GShard نهتنها توانست مدلهایی با بیش از ۶۰۰ میلیارد پارامتر را آموزش دهد، بلکه بستری فراهم کرد که مدلهای بسیار بزرگ بتوانند روی چندین TPU یا GPU بهصورت توزیعشده آموزش ببینند.
در این مقاله، نگاهی دقیق به GShard خواهیم داشت و بررسی میکنیم که چگونه این فناوری در ساخت مدلهای زبان بسیار بزرگ (مثل Switch Transformer یا PaLM) نقش محوری ایفا کرده است.
سرفصل های مقاله
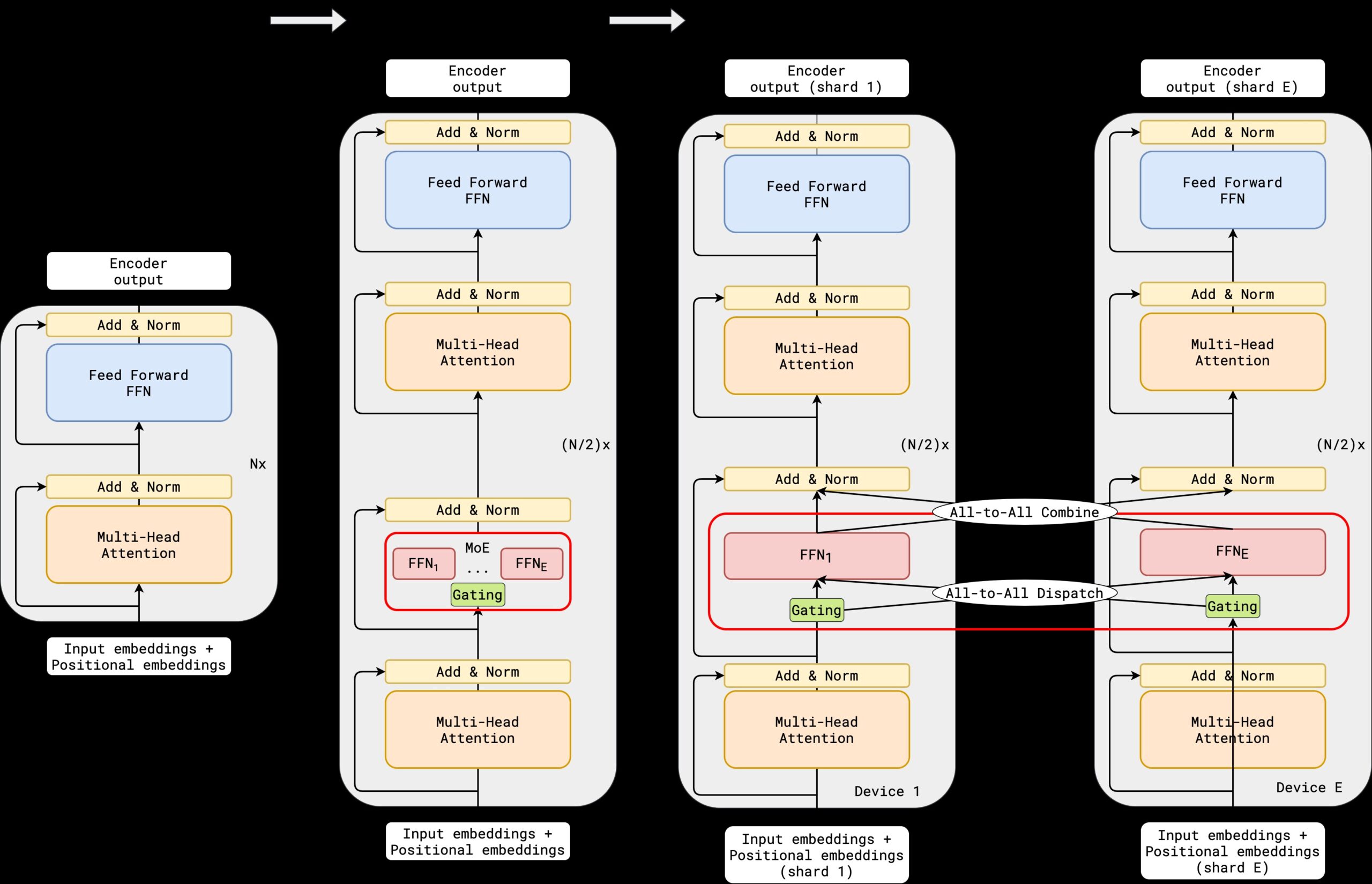
GShard یک چارچوب مقیاسپذیر و قابل انعطاف برای آموزش مدلهای ترنسفورمر بسیار بزرگ است که توسط تیم تحقیقاتی گوگل ارائه شد. این معماری از ترکیبی از تکنیکهای توزیعشده، برنامهریزی موازی و تخصصگرایی (expert specialization) استفاده میکند تا بتواند مدلها را بهصورت کارآمد و مؤثر آموزش دهد.
هدف اصلی GShard این بود که بدون نیاز به تغییر در ساختار اصلی مدلها، آنها را مقیاسپذیر کند تا روی چند دستگاه سختافزاری بهطور همزمان اجرا شوند. این معماری زمینهساز مدلهایی مانند Switch Transformer، M4 و PaLM بود که در نوع خود انقلابی محسوب میشوند.
آموزش هوش مصنوعی (صفر تا صد کار با ابزارهای هوش مصنوعی)
GShard از چندین مؤلفه کلیدی استفاده میکند:
در این سیستم، پارامترهای مدل بهصورت خودکار به شاردهای (تکههای) کوچکتر تقسیم شده و بین چندین دستگاه توزیع میشوند. این کار باعث میشود مصرف حافظه کاهش یافته و همزمانسازی سادهتر انجام شود.
در ساختار GShard، برای بهینهسازی مصرف منابع، از ایده معماری MoE نیز بهره گرفته میشود. در هر گام آموزشی، فقط تعدادی از “متخصصها” یا ماژولها فعال میشوند. به این ترتیب، مدل میتواند میلیاردها پارامتر داشته باشد ولی در هر گام فقط درصد کوچکی از آن استفاده شود.
GShard از فناوری XLA (Accelerated Linear Algebra) استفاده میکند تا بتواند محاسبات را بهشکل مؤثری روی TPUها اجرا کند. این روش موجب بهینهسازی حافظه و تسریع آموزش میشود.
| ویژگی | GShard | سایر معماریهای سنتی |
|---|---|---|
| مقیاسپذیری بالا | ✅ | محدود |
| پشتیبانی از MoE | ✅ | معمولاً ❌ |
| مصرف حافظه بهینه | ✅ | ❌ |
| یکپارچه با TensorFlow | ✅ | اغلب نیاز به تغییرات |
| قابلیت آموزش مدلهای بسیار بزرگ | ✅ | ❌ |
معماری GShard مبنای بسیاری از مدلهای بزرگ گوگل قرار گرفت. در ادامه به چند مدل برجسته اشاره میکنیم:
یکی از مشهورترین پروژههایی که بر پایه GShard ساخته شد. با استفاده از معماری MoE و GShard، این مدل توانست تا بیش از ۱ تریلیون پارامتر را مدیریت کند و در عین حال سرعت آموزش آن نسبت به BERT یا GPT-3 بیشتر باشد.
GShard در پروژه ترجمه ماشینی گوگل نیز استفاده شد. مدل M4 قادر بود بیش از ۱۰۰ زبان را بهصورت همزمان پشتیبانی کند و به لطف معماری GShard، کیفیت ترجمه در زبانهای کممنبع نیز بهبود یافت.
مدلی پیشرفته که از ساختار GShard برای مقیاسپذیری بهره گرفت. PaLM نهتنها عملکردی نزدیک به GPT-4 داشت، بلکه در بسیاری از وظایف زبان طبیعی، دقت و درک بالاتری ارائه داد.
هرچند GShard مزایای زیادی دارد، اما پیادهسازی آن خالی از چالش نیست:
با این حال، تیم گوگل با ارائه مستندات و ابزارهای متنباز سعی کرده این چالشها را تا حد ممکن کاهش دهد.
در دنیای هوش مصنوعی، راهحلهای دیگری نیز برای مقیاسپذیری وجود دارد مانند Megatron-LM از NVIDIA، DeepSpeed از مایکروسافت و ZeRO++ از HuggingFace. اما GShard چند تفاوت کلیدی دارد:
با گسترش مدلهای چندمنظوره و عاملهای هوش مصنوعی (AI Agents)، نیاز به چارچوبهایی مانند GShard بیشتر از همیشه احساس میشود. در آینده، این معماری میتواند با کمک به توسعه مدلهای چندماژوله، نقش مهمی در ساخت مدلهای مسئول، اخلاقمدار و قابل کنترل ایفا کند.
همچنین انتظار میرود که نسخههای سبکتر و متنباز GShard برای آموزش در مقیاس کوچکتر نیز منتشر شود تا توسعهدهندگان مستقل بتوانند از آن بهره ببرند.
مدل GShard را باید یکی از مهمترین نوآوری های گوگل در زمینه آموزش مدلهای زبانی بزرگ دانست. این چارچوب با استفاده از استراتژیهای هوشمند توزیع پارامتر و ساختار MoE، توانسته مرزهای پردازش زبان طبیعی را فراتر ببرد. در آینده، GShard بدون شک پایهگذار نسل بعدی مدلهای مولد، ترجمه، خلاصهسازی و Agentهای چندوظیفهای خواهد بود.

با رشد سریع هوش مصنوعی و گسترش استفاده از مدلهای زبانی، نیاز به روشی ساده و سریع برای اتصال این مدلها به ابزارها...

با گسترش ابزارهای هوش مصنوعی، دو مفهوم پرکاربرد بیشتر از همیشه شنیده میشود: AI Agent و MCP. هرچند هر دو به نحوی به...

پرامپتها (Prompts) قلب تعامل ما با مدلهای هوش مصنوعی هستند. نحوه طراحی پرامپت میتواند خروجی مدل را به شدت تحت تأثیر قرار دهد....

با گسترش هوش مصنوعی، شرکتها به دنبال مدلهایی هستند که هم کارایی بالا داشته باشند و هم در منابع سختافزاری سبکتر عمل کنند....

جامعه توسعهدهندگان همیشه به دنبال ابزارها و پرامپتهایی است که کار با مدلهای هوش مصنوعی را سادهتر و کارآمدتر کنند. یکی از پلتفرمهایی...