
2دقیقه
آنچه در این مقاله میخوانید [پنهانسازی]
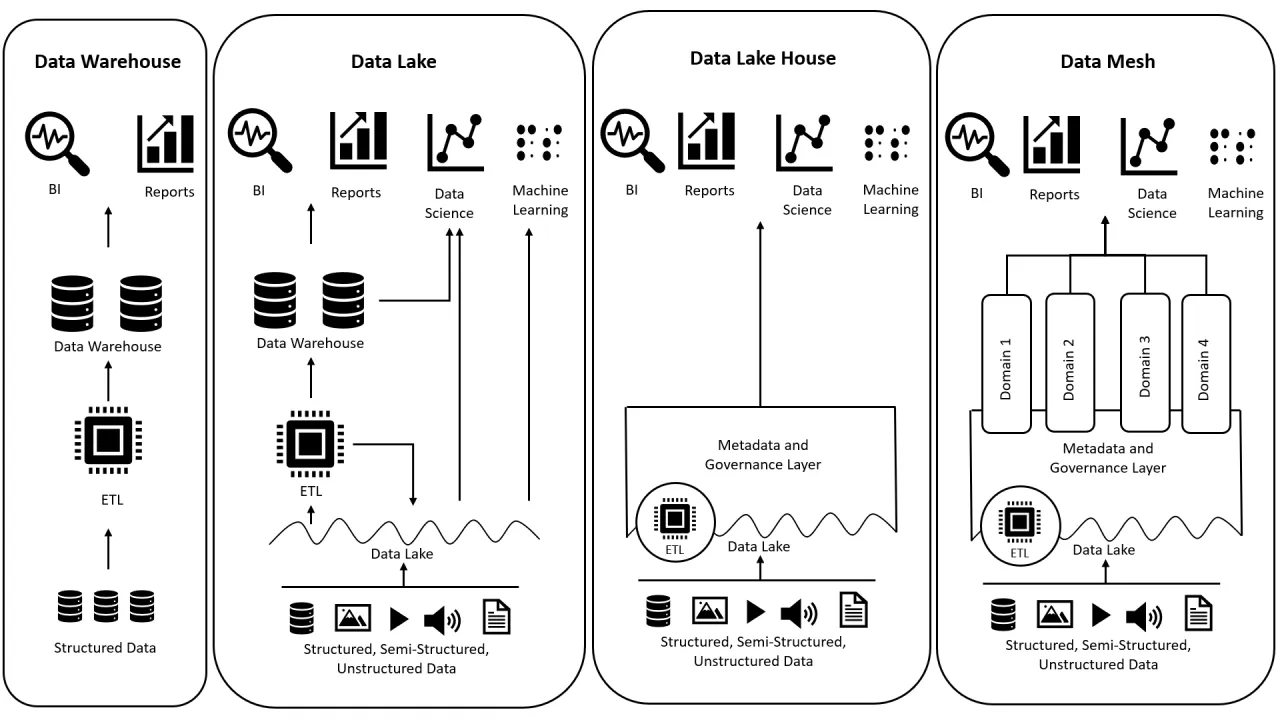
با رشد روزافزون دادهها در سازمانها، معماریهای مختلفی برای ذخیرهسازی، پردازش و تحلیل دادهها شکل گرفته است. در گذشته، تنها Data Warehouse (انبار داده) بهعنوان راهکار اصلی مورد استفاده بود. اما با ظهور دادههای متنوع و حجم عظیم اطلاعات، معماریهای جدیدتری مثل Data Lake، Data Lakehouse و در نهایت Data Mesh به وجود آمدند. هرکدام از این رویکردها نقاط قوت و ضعف خاص خود را دارند و انتخاب بین آنها به نیازهای سازمان بستگی دارد. در این مقاله بر اساس نقشهای که در تصویر میبینید، این معماریها را مقایسه میکنیم.
سرفصل های مقاله
Data Warehouse (انبار داده) قدیمیترین و شناختهشدهترین معماری داده است.
🔹 مزیتها: دقت بالا، ساختار استاندارد، مناسب برای تحلیلهای مدیریتی.
🔹 محدودیتها: انعطافپذیری پایین برای دادههای نیمهساختیافته و غیرساختیافته.
با رشد دادههای متنوع (متنی، تصویری، لاگها و…)، نیاز به ساختار منعطفتر ایجاد شد. اینجا بود که Data Lake بهوجود آمد.
مزیتها: انعطاف بالا، پشتیبانی از انواع داده، مناسب برای یادگیری ماشین.
محدودیتها: مدیریت دشوار، ریسک ایجاد «دریاچه گلآلود» (Data Swamp) در صورت نبود حاکمیت داده.
Data Lakehouse تلاشی است برای ترکیب نقاط قوت معماری Data Warehouse و Data Lake.
مزیتها: ترکیب ساختار منظم Data Warehouse با انعطاف Data Lake.
محدودیتها: هنوز معماری نسبتاً جدیدی است و نیازمند ابزارهای خاص (مثل Databricks Lakehouse).
جدیدترین رویکرد در معماری داده، Data Mesh است. این معماری به جای تمرکزگرایی، به تمرکززدایی (Decentralization) روی میآورد.
مزیتها: مقیاسپذیری بالا، تقسیم مسئولیتها، جلوگیری از گلوگاه مرکزی.
محدودیتها: پیادهسازی پیچیده، نیازمند فرهنگ سازمانی و تیمهای داده بالغ.
| ویژگی | Data Warehouse | Data Lake | Data Lakehouse | Data Mesh |
|---|---|---|---|---|
| نوع داده | ساختیافته | همه نوع داده | همه نوع داده | همه نوع داده |
| تمرکز معماری | متمرکز | متمرکز | نیمهمتمرکز | غیرمتمرکز (دامنهای) |
| کاربرد اصلی | گزارشگیری و BI | ذخیرهسازی و تحلیل | BI + Data Science | BI + Data Science + مالکیت دامنه |
| انعطافپذیری | پایین | بالا | بالا | بسیار بالا |
| چالشها | انعطاف کم | مدیریت سخت | ابزار محدود | فرهنگ سازمانی، هماهنگی تیمی |
معماری داده در حال تکامل است:
انتخاب بین این معماریها به نیاز سازمان، حجم داده، تنوع دادهها و فرهنگ سازمانی بستگی دارد.

فلاترفلو یک پلتفرم بصری و قدرتمند برای ساخت اپلیکیشنهای موبایل و وب است که بر پایه فریمورک محبوب فلاتر بنا شده و به...

Model Context Protocol AI2SQL یک استاندارد باز و نوین است که به مدلهای زبانی بزرگ اجازه میدهد به طور مستقیم و ایمن با...

Firebase Python integration راهکار قدرتمندی است که به توسعه دهندگان هوش مصنوعی اجازه می دهد داده های سنگین و بلادرنگ خود را به...

Python Firebase database یک راهکار ابری قدرتمند برای ذخیره سازی و همگام سازی دادهها به صورت بلادرنگ است که به توسعه دهندگان اجازه...

اگر قصد داری یک اپلیکیشن موبایل یا وب بسازی اما نمیخواهی درگیر ساخت سرور، مدیریت دیتابیس و توسعه API شوی، Firebase می تواند...