
2دقیقه
آنچه در این مقاله میخوانید [پنهانسازی]
یکی از نقاط عطف مهم در تاریخچه هوش مصنوعی و یادگیری عمیق، معرفی الگوریتم پس انتشار خطا یا Backpropagation بوده است. این روش که برای بهینهسازی وزنها در شبکههای عصبی به کار میرود، باعث شد مدلهای هوش مصنوعی بتوانند وظایف پیچیدهای مانند تشخیص تصویر، پردازش زبان طبیعی و پیشبینی سریهای زمانی را با دقت بسیار بالا انجام دهند. قبل از این الگوریتم، آموزش شبکههای چندلایه با مشکل بزرگی به نام کمرنگ شدن گرادیان یا عدم پایداری یادگیری مواجه بود.
در این مقاله، به زبانی ساده و کاربردی، به بررسی مفهوم، نحوه عملکرد و اهمیت الگوریتم پسانتشار خطا میپردازیم و همچنین مزایا، محدودیتها و کاربردهای آن را مرور میکنیم.
سرفصل های مقاله
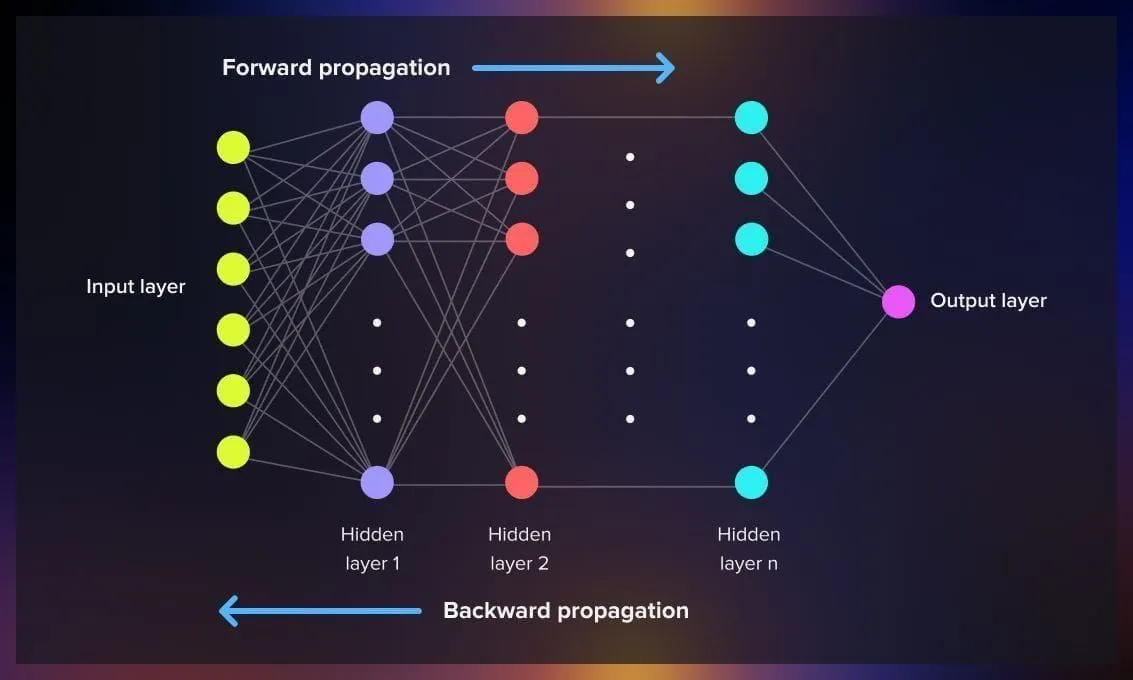
پسانتشار خطا یک روش ریاضی برای محاسبه تغییرات لازم در وزنهای شبکه عصبی است تا خروجی مدل به پاسخ درست نزدیکتر شود. این الگوریتم در اصل یک پیادهسازی از قانون زنجیرهای مشتقها در حساب دیفرانسیل است که به ما اجازه میدهد از لایه خروجی به سمت لایه ورودی، خطا را به عقب منتقل کنیم.
به زبان ساده، پس از محاسبه خروجی مدل و مقایسه آن با مقدار واقعی (Label)، اختلاف یا همان خطا مشخص میشود. سپس با استفاده از مشتقگیری از تابع خطا نسبت به هر وزن، الگوریتم مشخص میکند که هر وزن چه مقدار باید تغییر کند.
ابتدا ورودیها به شبکه داده میشوند و با گذر از لایههای مختلف، خروجی مدل محاسبه میشود.
خروجی مدل با مقدار هدف مقایسه شده و مقدار خطا با استفاده از یک تابع هزینه (مانند MSE یا Cross-Entropy) محاسبه میشود.
با استفاده از قانون زنجیرهای مشتقها، گرادیان تابع هزینه نسبت به وزنهای هر لایه محاسبه و از لایه خروجی به سمت ورودی منتقل میشود.
وزنها با استفاده از الگوریتمهای بهینهسازی مانند Gradient Descent یا Adam تغییر داده میشوند.
آموزش هوش مصنوعی (صفر تا صد کار با ابزارهای هوش مصنوعی)
الگوریتم پسانتشار خطا ستون فقرات تمام شبکههای عصبی مدرن است. بدون این روش، آموزش مدلهایی مانند GPT، BERT، ResNet و Transformerها غیرممکن یا بسیار کند بود. این الگوریتم توانسته یادگیری چندلایه را به شکلی بهینه و پایدار انجام دهد و مسیر را برای توسعه هوش مصنوعی پیشرفته هموار کند.
الگوریتم پسانتشار خطا یکی از بنیادیترین نوآوریها در یادگیری عمیق است که آموزش شبکههای عصبی چندلایه را ممکن ساخته است. این روش با ترکیب ریاضیات و بهینهسازی، هوش مصنوعی را از مدلهای ساده به سیستمهای پیچیده و قدرتمند امروزی رسانده است. با وجود محدودیتهایی مانند مشکل گرادیان محو، پیشرفتهای جدید در معماریها و روشهای بهینهسازی باعث شده این الگوریتم همچنان نقش کلیدی در آموزش مدلهای هوش مصنوعی ایفا کند.

با رشد سریع هوش مصنوعی و گسترش استفاده از مدلهای زبانی، نیاز به روشی ساده و سریع برای اتصال این مدلها به ابزارها...

با گسترش ابزارهای هوش مصنوعی، دو مفهوم پرکاربرد بیشتر از همیشه شنیده میشود: AI Agent و MCP. هرچند هر دو به نحوی به...

پرامپتها (Prompts) قلب تعامل ما با مدلهای هوش مصنوعی هستند. نحوه طراحی پرامپت میتواند خروجی مدل را به شدت تحت تأثیر قرار دهد....

با گسترش هوش مصنوعی، شرکتها به دنبال مدلهایی هستند که هم کارایی بالا داشته باشند و هم در منابع سختافزاری سبکتر عمل کنند....

جامعه توسعهدهندگان همیشه به دنبال ابزارها و پرامپتهایی است که کار با مدلهای هوش مصنوعی را سادهتر و کارآمدتر کنند. یکی از پلتفرمهایی...