چگونه KV Caching سرعت مدلهای زبانی مثل GPT را چند برابر میکند
4دقیقه
آنچه در این مقاله میخوانید [پنهانسازی]
اگر با مدلهای زبانی بزرگ مثل GPT، Claude یا Gemini کار کرده باشید، احتمالاً متوجه شدهاید که این مدلها با وجود میلیاردها پارامتر، پاسخها را در چند ثانیه تولید میکنند. اما سؤال اینجاست: چطور چنین حجم عظیمی از محاسبات در لحظه انجام میشود؟
پاسخ در یک تکنیک هوشمندانه به نام KV Caching نهفته است — روشی که مثل یک حافظه میانبر عمل میکند و مانع از تکرار محاسبات غیرضروری میشود. در این مقاله به زبان ساده توضیح میدهیم KV Caching چیست، چطور کار میکند و چرا یکی از دلایل اصلی سرعت فوقالعاده مدلهای زبانی مدرن است.
سرفصل های مقاله
KV Caching چیست؟
در مدلهای ترنسفورمر (مثل GPT)، هر توکن ورودی باید با تمام توکنهای قبلی تعامل داشته باشد تا معنای جمله را درک کند.
این تعامل از طریق مکانیزم Attention انجام میشود که سه مؤلفه اصلی دارد:
- Query (پرسوجو)
- Key (کلید)
- Value (مقدار)
در فرآیند تولید متن، مدل برای هر توکن جدید باید تمام Query، Key و Valueهای قبلی را دوباره محاسبه کند — کاری بسیار سنگین و زمانبر!
اما KV Caching این مشکل را حل میکند. این روش میگوید:
«وقتی Key و Value توکنهای قبلی را قبلاً محاسبه کردهایم، چرا دوباره بسازیم؟ کافی است آنها را در حافظه ذخیره کنیم و مستقیماً استفاده کنیم.»
به این ترتیب، مدل فقط Query مربوط به توکن جدید را محاسبه میکند و از Key و Value ذخیرهشده برای سایر توکنها بهره میبرد.
ایده اصلی KV Caching به زبان ساده
فرض کنید GPT دارد جملهای را کلمهبهکلمه تولید میکند.
در مرحله اول، توکن اول را پردازش میکند و Key و Value آن را میسازد.
در مرحله دوم، باید توکن دوم را پیشبینی کند. بهجای بازسازی Key و Value توکن اول، مدل از حافظه قبلی آنها استفاده میکند.
در هر مرحله، فقط Key و Value توکن جدید به کش اضافه میشوند.
این یعنی:
- هیچچیز دوباره محاسبه نمیشود.
- تمام تاریخچه ورودی فقط یکبار پردازش میشود.
- مدل با هر توکن جدید، فقط چند عمل ماتریسی ساده انجام میدهد.
چرا این موضوع حیاتی است؟
در حالت عادی، اگر بخواهیم ۱۰۰ توکن خروجی تولید کنیم، مدل باید در هر مرحله کل توکنهای قبلی را دوباره پردازش کند.
یعنی برای ۱۰۰ توکن، ۱۰۰ بار محاسبه روی ۱۰۰ توکن انجام میشود — چیزی در حد ۱۰٬۰۰۰ بار عملیات Attention!
اما با KV Caching، این عدد به حدود ۱۰۰ بار کاهش پیدا میکند، چون محاسبات تکراری حذف شدهاند.
نتیجه؟
افزایش سرعت تا چند برابر
کاهش مصرف GPU و RAM
افزایش بازده در پاسخهای بلادرنگ
به همین دلیل است که مدلهای زبانی جدید میتوانند در کسری از ثانیه پاسخ دهند، حتی وقتی ورودیهای طولانی دارند.
ساختار فنی KV Cache
در هر لایه از ترنسفورمر، هنگام تولید توکن جدید، دو ماتریس ساخته میشود:
- ماتریس K (Key)
- ماتریس V (Value)
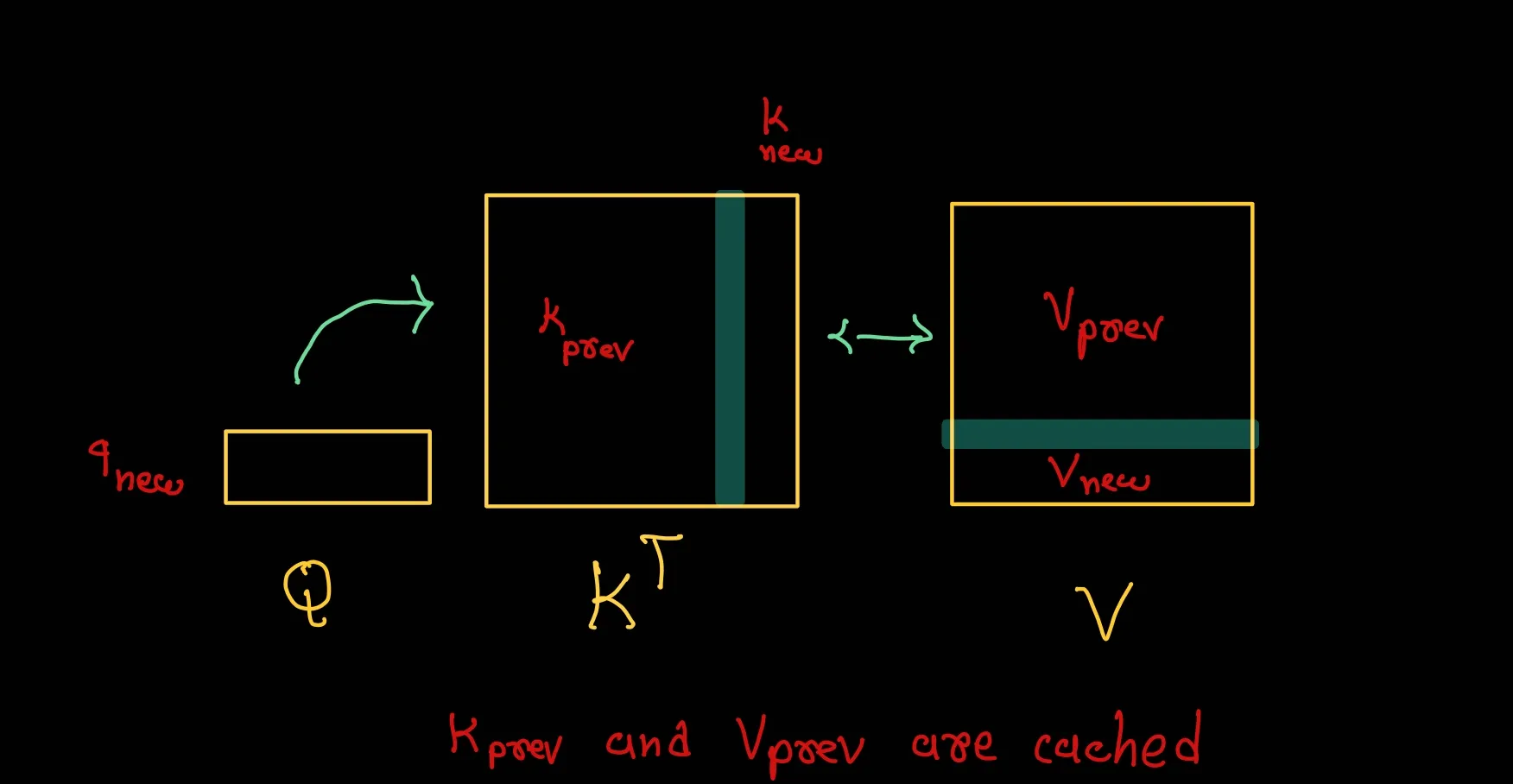
در مدلهای مجهز به KV Cache، این دو ماتریس در حافظه موقت GPU ذخیره میشوند.
در مراحل بعدی، مدل فقط ماتریس Query جدید را محاسبه میکند و آن را با Key و Value ذخیرهشده ترکیب میکند تا خروجی Attention بهدست آید.
به بیان دیگر، مدل یک حافظه پویا دارد که همراه با تولید توکن رشد میکند، اما محاسبات قبلی را تکرار نمیکند.
مثال ساده
فرض کنید مدل باید جملهی زیر را بنویسد:
“Machine learning is amazing.”
بدون KV Cache، مدل برای پیشبینی هر کلمه باید از اول کل جملهی قبلی را بررسی کند.
اما با KV Cache:
- در مرحله اول، Key و Value مربوط به “Machine” ساخته و ذخیره میشوند.
- در مرحله دوم، فقط Query برای “learning” محاسبه میشود و مدل از Key و Value مرحله قبل استفاده میکند.
- همین فرایند برای “is” و “amazing” ادامه مییابد.
در نهایت، مدل فقط دادهی جدید را پردازش کرده و از حافظهی قبلی برای بقیهی محاسبات استفاده کرده است.
KV Caching در مدلهای واقعی
تقریباً تمام مدلهای زبانی مدرن از این تکنیک استفاده میکنند:
- GPT-3.5 و GPT-4 برای پاسخهای سریعتر و مکالمههای طولانیتر.
- Claude 3 و Gemini 1.5 Pro برای تعامل پیوسته در مکالمات چندمرحلهای.
- Mistral و LLaMA 3 برای کاهش زمان پاسخ در APIهای بلادرنگ.
در واقع، KV Cache یکی از دلایلی است که مدلهای امروزی میتوانند حتی ورودیهای چند هزار توکنی را در زمان کوتاه تحلیل کنند.
محدودیت های KV Caching
هرچند این روش بسیار مؤثر است، اما بدون چالش هم نیست:
- مصرف حافظه: هرچه طول ورودی یا پاسخ بیشتر باشد، حجم KV Cache هم افزایش مییابد.
- محدودیت طول زمینه (Context Length): به دلیل محدودیت حافظه GPU، مدلها نمیتوانند بینهایت توکن ذخیره کنند.
- نیاز به هماهنگی سختافزار: برای عملکرد بهینه، GPUها باید بتوانند کش را سریع ذخیره و بازیابی کنند.
با این حال، شرکتهایی مثل OpenAI، Anthropic و Google در حال توسعه روشهای فشردهسازی KV Cache هستند تا این محدودیتها کاهش یابد.
آینده KV Caching؛ حافظه پویا برای مدلهای هوشمندتر
در نسل بعدی مدلها، KV Caching با حافظه بلندمدت (Long-term Memory) ترکیب میشود.
یعنی مدل میتواند نهفقط محاسبات اخیر، بلکه مفاهیم یا گفتوگوهای گذشته را نیز بهصورت هوشمند ذخیره و بازیابی کند.
این رویکرد در پروژههایی مثل GPT Memory و Claude Memory System در حال پیادهسازی است.
جمع بندی
KV Caching یکی از نوآورانهترین ایدهها در معماری مدلهای زبانی است که باعث افزایش چشمگیر سرعت و کاهش مصرف منابع میشود.
با ذخیره Key و Value توکنهای قبلی، مدل دیگر مجبور نیست محاسبات را از ابتدا تکرار کند و در نتیجه میتواند پاسخها را تقریباً بهصورت بلادرنگ تولید کند.
بدون KV Cache، مدلهایی مانند GPT یا Claude عملاً نمیتوانستند در مقیاس فعلی عمل کنند.