دیتاست فارسی ParsOffensive برای تشخیص محتوای توهین آمیز
2دقیقه
آنچه در این مقاله میخوانید [پنهانسازی]
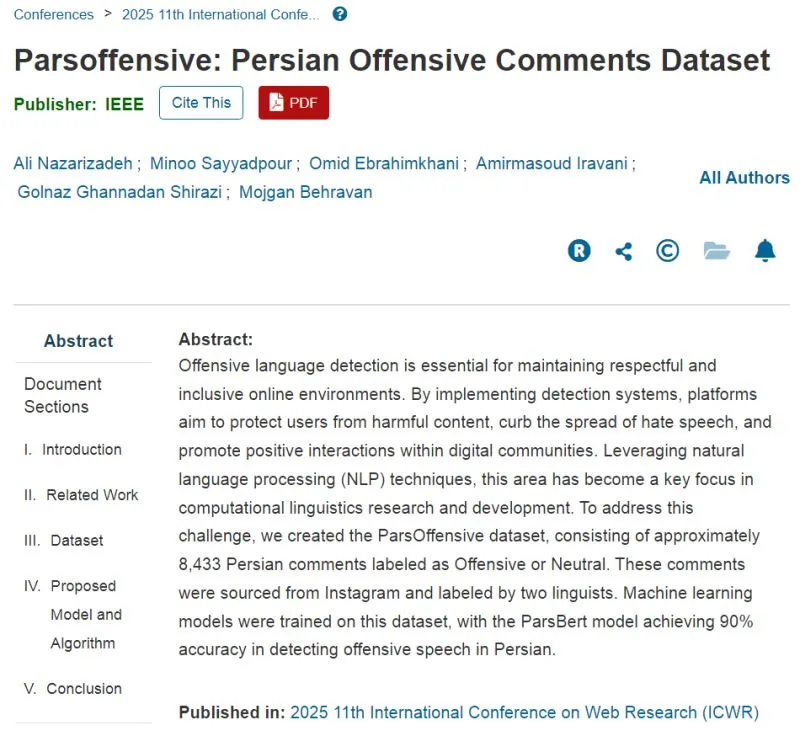
تشخیص محتوای توهینآمیز در زبان فارسی یکی از چالشهای مهم در پردازش زبان طبیعی (NLP) است. برخلاف زبان انگلیسی که دیتاستهای متنوعی برای شناسایی محتوای نامناسب وجود دارد، منابع فارسی بسیار محدود هستند. همین مسئله باعث شده توسعه سیستمهای فیلترینگ خودکار و هوش مصنوعی در فضای فارسی سختتر و زمانبر باشد. دیتاست ParsOffensive با هدف رفع این کمبود ارائه شده است تا پژوهشگران و توسعهدهندگان بتوانند مدلهای دقیقتری برای شناسایی و مدیریت محتوای توهینآمیز بسازند.
سرفصل های مقاله
معرفی ParsOffensive
رفقا، تشخیص محتوای توهینآمیز تو فارسی سخته و وقتگیره 🫠. امروز میخوایم یه دیتاست فوقالعاده برای تشخیص محتوای توهینآمیز در فارسی رو بهتون معرفی کنیم! با این دیتاست، میتونید مدلهای هوش مصنوعی رو برای شناسایی خودکار پیامهای نامناسب آموزش بدید و یه فضای آنلاین سالمتر بسازید 🤩.
این دیتاست مجموعهای از کامنتهای فارسی است که بهصورت دستی برچسبگذاری شده و شامل نمونههای واقعی از گفتگوهای کاربران در شبکههای اجتماعی است.
مشخصات دیتاست ParsOffensive
- حجم داده: بیش از ۱۰ هزار توییت فارسی برچسبخورده
- برچسبها: توهینآمیز / عادی + دستهبندیهای دقیقتر برای تشخیص بهتر
- فرمت فایل: Excel (.xlsx)
- منبع داده: کامنتهای واقعی کاربران در اینستاگرام و توییتر
- موضوعات: سیاست، فرهنگ، ورزش، رویدادهای روز
- فرآیند برچسبگذاری: دو زبانشناس متخصص + بازبینی چندمرحلهای برای افزایش دقت
🔗 لینک دیتاست: ParsOffensive Dataset
اهمیت ParsOffensive در NLP فارسی
تشخیص محتوای توهینآمیز تنها برای فیلترینگ شبکههای اجتماعی نیست؛ بلکه میتواند کاربردهای گستردهای داشته باشد:
- مدیریت فضای مجازی سالمتر از طریق شناسایی و حذف کامنتهای نامناسب
- پشتیبانی از پلتفرمها برای ایجاد محیط امن و جلوگیری از آزار کلامی
- آموزش مدلهای یادگیری ماشین برای تشخیص خودکار گفتار توهینآمیز
- کمک به تحقیقات دانشگاهی در حوزه جامعهشناسی و تحلیل شبکههای اجتماعی
ساختار فایل دیتاست
فایل اصلی بهنام ParsOffensive.xlsx شامل متن کامنتها و برچسبهای مرتبط است. این فایل در پوشه اصلی مخزن قرار دارد و بهسادگی قابل بارگذاری و استفاده است.
نمونه کد استفاده از دیتاست
برای استفاده از این دیتاست در پروژههای یادگیری ماشین کافی است آن را با کتابخانه pandas بارگذاری کنید:
import pandas as pd
# بارگذاری دیتاست
df = pd.read_excel("ParsOffensive.xlsx")
# نمایش چند ردیف اول
print(df.head())
کاربردهای پژوهشی و عملی
دیتاست ParsOffensive میتواند پایهای برای پروژههای مختلف باشد:
- توسعه چتباتهای هوشمند که بتوانند پاسخهای محترمانه و ایمن ارائه دهند.
- ساخت فیلترهای خودکار برای شبکههای اجتماعی فارسی.
- ایجاد ابزارهای تحلیل احساسات و رفتار کاربران در موضوعات حساس.
- پر کردن شکاف منابع NLP فارسی برای تحقیقات آکادمیک و کاربردی.
جمع بندی
ParsOffensive یکی از اولین دیتاستهای جامع فارسی برای تشخیص محتوای توهینآمیز است. این مجموعه با بیش از ۱۰ هزار نمونه واقعی و برچسبگذاری تخصصی، ابزاری ارزشمند برای توسعه سیستمهای هوش مصنوعی، فیلترینگ خودکار و تحقیقات NLP فارسی به شمار میرود. با بهرهگیری از ParsOffensive، میتوان گام بزرگی در جهت ساخت محیطهای دیجیتال سالمتر برداشت.