
معماری MoE در مدل های هوش مصنوعی
4دقیقه
آنچه در این مقاله میخوانید [پنهانسازی]
با رشد سریع مدل های زبانی بزرگ و سیستمهای هوش مصنوعی مولد، یکی از چالشهای اصلی، تعادل میان افزایش توان محاسباتی و حفظ بهرهوری است. وقتی یک مدل هوش مصنوعی میلیاردها پارامتر دارد، اجرای تمام آنها برای هر ورودی، هم پرهزینه است و هم غیربهینه. معماری MoE (مخفف Mixture of Experts) با ایدهای هوشمندانه وارد میدان شده: استفاده از «تعدادی متخصص» که فقط در زمان نیاز فعال میشوند.
این رویکرد نهتنها منابع محاسباتی را بهینه میکند، بلکه امکان ساخت مدلهای بسیار بزرگ و دقیقتر را فراهم میسازد، بدون اینکه نیاز به اجرای کامل همه اجزای مدل در هر بار پردازش باشد.
سرفصل های مقاله
- معماری MoE چیست؟
- مزایای اصلی معماری MoE
- صرفهجویی در مصرف منابع
- مقیاسپذیری بسیار بالا
- بهبود عملکرد مدل
- یادگیری تخصصیتر
- نحوه عملکرد معماری MoE
- مثالهایی از استفاده موفق MoE
- GShard و Switch Transformer از گوگل
- M6-T از بایدو
- CoDi از مایکروسافت
- چالشهای موجود در پیادهسازی معماری MoE
- بار نامتعادل بین متخصصها
- پیچیدگی در آموزش
- پیادهسازی سخت در محیطهای تولیدی
- مقایسه MoE با مدلهای Dense
- آینده معماری MoE در هوش مصنوعی
- نتیجه گیری
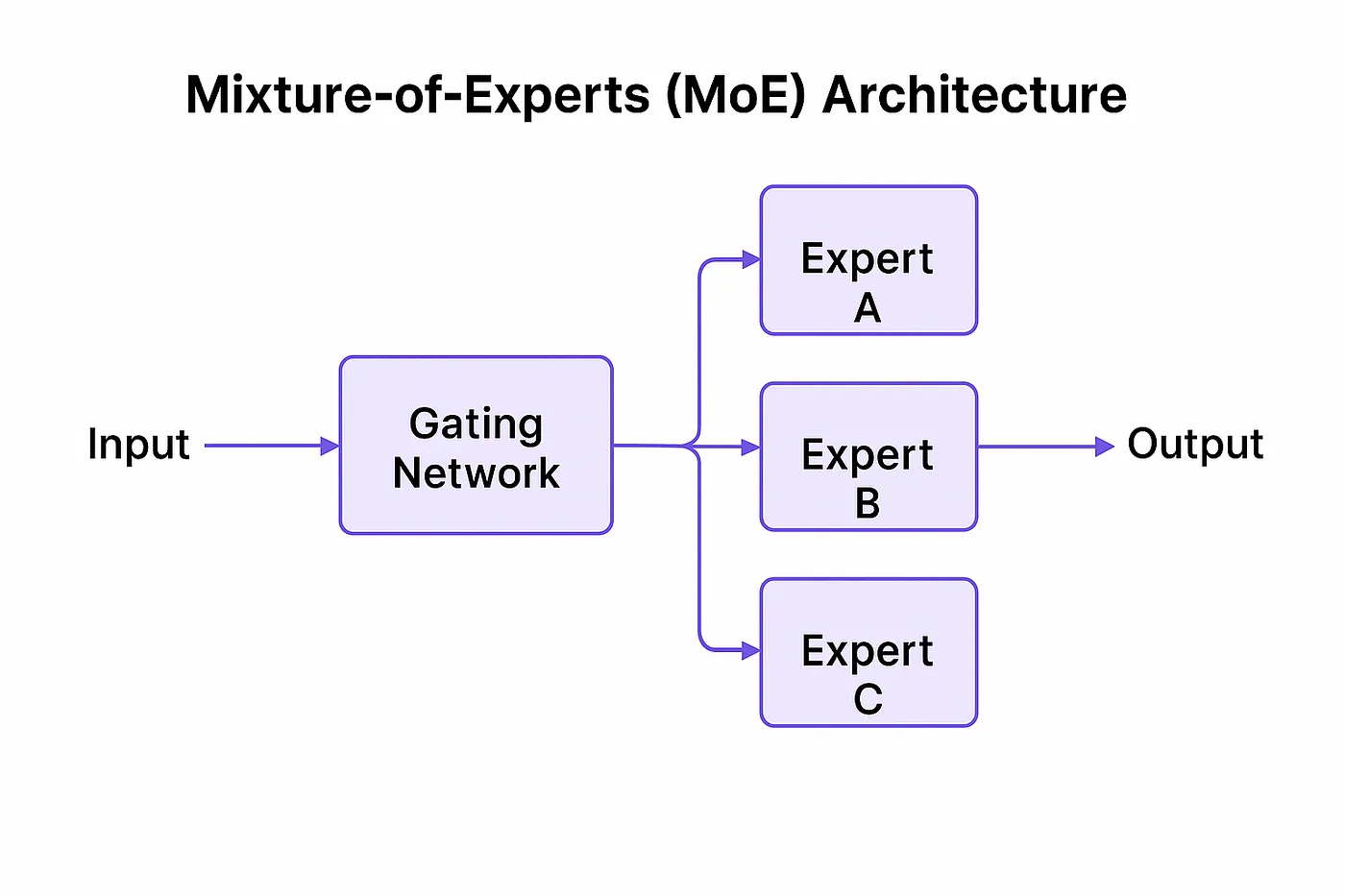
معماری MoE چیست؟
معماری MoE نوعی معماری شبکه عصبی است که در آن بهجای اجرای یک مدل یکپارچه، شبکه از مجموعهای از زیرشبکهها یا ماژولها به نام «متخصص» (Expert) تشکیل میشود. در هر مرحله، یک سیستم «دروازهبان» (Gating Mechanism) تصمیم میگیرد که کدام یک از این متخصصها برای پردازش داده فعلی فعال شوند.
به عبارت سادهتر:
بهجای اینکه همهی نورونها برای پردازش یک ورودی فعالیت کنند، فقط آنهایی که «در این لحظه» بهترین عملکرد را دارند، به کار گرفته میشوند.
مزایای اصلی معماری MoE
صرفهجویی در مصرف منابع
یکی از بزرگترین مزایای معماری MoE، کاهش مصرف حافظه و توان پردازشی است. تنها درصد کوچکی از مدل برای هر ورودی فعال میشود، اما خروجی نهایی بهاندازه مدلی کامل و بزرگ قدرتمند است.
مقیاسپذیری بسیار بالا
به دلیل ساختار ماژولار، میتوان تعداد متخصصها را بهصورت تصاعدی افزایش داد، بدون اینکه نیاز باشد در هر مرحله تمام آنها اجرا شوند. این مزیت مهمی برای آموزش مدلهایی با میلیاردها پارامتر است.
بهبود عملکرد مدل
معماری MoE این امکان را فراهم میکند که هر متخصص در یک زیرحوزه خاص از دادهها تخصص پیدا کند. مثلاً یکی برای متون حقوقی، دیگری برای زبان عامیانه، و سومی برای مسائل ریاضی.
یادگیری تخصصیتر
با تقسیم وظایف میان متخصصها، هر کدام در یک نوع وظیفه یا موضوع خاص خبره میشوند و این موجب میشود مدل بهصورت کلی دقت بیشتری داشته باشد.
نحوه عملکرد معماری MoE
معماری MoE از سه بخش اصلی تشکیل شده است:
- شبکه ورودی و استخراج ویژگیها (Feature Extractor)
- مکانیزم دروازهبان (Gating Mechanism)
- متخصصها (Experts)
در هر مرحله، گیتینگ مکانیزم با توجه به ورودی تصمیم میگیرد که چه تعدادی (مثلاً دو عدد از ۶۴ متخصص) فعال شوند. سپس فقط همان متخصصها خروجی میدهند و نتیجه نهایی با وزندهی مناسب ترکیب میشود.
مثالهایی از استفاده موفق MoE
GShard و Switch Transformer از گوگل
مدل GShard اولین نمونه موفقی بود که نشان داد معماری MoE در مقیاس بسیار بزرگ قابل اجرا است. نسخه بعدی، Switch Transformer، توانست با استفاده از بیش از ۱۰۰ میلیارد پارامتر، عملکردی بسیار بهینه و سریعتر از مدلهای سنتی ارائه دهد.
M6-T از بایدو
این مدل چینی با بیش از ۱۰ تریلیون پارامتر یکی از بزرگترین مدلهای ساختهشده با معماری MoE است که در حوزههای مختلف از پردازش زبان گرفته تا بینایی ماشین عملکرد چشمگیری داشته است.
CoDi از مایکروسافت
CoDi مدلی چندوجهی است که همزمان با تصویر، متن و صوت کار میکند. استفاده از معماری MoE به آن کمک کرده که برای هر نوع ورودی از متخصص متفاوتی استفاده کند.
چالشهای موجود در پیادهسازی معماری MoE
بار نامتعادل بین متخصصها
یکی از چالشهای رایج، این است که بعضی متخصصها بیشازحد فعال میشوند و برخی دیگر بلااستفاده باقی میمانند. این مشکل با تکنیکهایی مثل توازن بار (Load Balancing Loss) تا حدی حل شده است.
پیچیدگی در آموزش
آموزش مدلهایی با ساختار MoE نیازمند تکنیکهای خاص مانند تقسیمبندی پارامترها، همگامسازی بین گرههای پردازشی و مدیریت حافظه پیچیدهتری است.
پیادهسازی سخت در محیطهای تولیدی
اجرای این مدلها بهصورت مقیاسپذیر در محیطهای real-time چالشهای مهندسی فراوانی دارد، بهویژه در سیستمهایی با محدودیت منابع.
مقایسه MoE با مدلهای Dense
| ویژگی | مدل Dense (یکپارچه) | معماری MoE |
|---|---|---|
| تعداد پارامتر فعال در هر گام | همه پارامترها | فقط تعداد محدودی |
| دقت در دادههای متنوع | متوسط | بسیار بالا |
| مصرف منابع | زیاد | بهینه |
| انعطافپذیری | کم | بالا |
| مقیاسپذیری | محدود | بسیار زیاد |
آینده معماری MoE در هوش مصنوعی
با توجه به روند فعلی، انتظار میرود معماری MoE در مدلهای مولتیمدال، عاملهای هوشمند و مدلهای مقیاس بزرگ نقش حیاتی داشته باشد. همچنین با ترکیب این معماری با تکنیکهای دیگر مانند RLHF (یادگیری با تقویت از بازخورد انسانی) و یادگیری مداوم (Continual Learning)، نسل جدیدی از مدلهای بسیار کارآمد پدید خواهد آمد.
نتیجه گیری
معماری MoE یکی از نوآورانهترین و مؤثرترین روشها در ساخت مدلهای هوش مصنوعی در مقیاس بزرگ است. این رویکرد با الهام از ساختار مغز انسان که در آن نواحی مختلف برای وظایف خاص فعال میشوند، تلاش میکند سیستمهای هوشمندتر، سریعتر و تخصصیتری بسازد. با رشد ابزارهای پردازش ابری و معماریهای توزیعشده، استفاده از MoE نهتنها آسانتر، بلکه روزبهروز رایجتر نیز خواهد شد. در آیندهای نزدیک، این معماری ممکن است به استاندارد اصلی در توسعه مدلهای زبانی بزرگ تبدیل شود.




